
Introduction
토양 탄소(soil carbon)는 유기물을 구성하는 주성분으로 토양의 물리, 화학적 특징을 표현하는 지표가 된다. 토양에 있는 유기탄소는 대기중의 약 2배 이상(Batjes, 1996)으로 가장 큰 탄소 저장고이며 기후변화의 감축수단으로 주목받고 있다(Brady and Weil, 2008). 이에, 각국의 유기탄소의 저장량을 국가온실 가스 인벤토리와 유엔 사막화방지협약에 보고하고 있는 실정이다. 단, 전 지구적 탄소 저장량을 산정함에 있어 통일된 산정방법은 국가간 비교와 저장 용량을 평가함에 있어 매우 중요하다.
과거에 토양정보를 맵핑하는 기술은 샘플링 지점만의 정보를 표현하거나, 지점을 필지단위로 표현하여 보여주는 방식이다. 즉, 필지와 필지사이의 샘플링되지 않은 지점에 대한 정보를 예측할 수가 없다. 지리통계에서 보편적으로 공간 보간법을 통해 미측정지점을 맵핑하기도 하지만 더 과학적인 방법이 요구되어 왔다. 디지털 토양 맵핑 기술(digital soil mapping technology, DSM)은 토양 속성 정보와 그에 영향을 미치는 환경정보와의 관계를 바탕으로 통계적으로 예측해 내고 맵핑하는 기술이다(Lagacherie and McBratney, 2006; Hempel et al., 2008; Minasny et al., 2013). 환경정보는 토양생성에 영향을 미치는 인자로써, 탄소 값을 예측하는 환경변량(environmental covariate)로 쓰인다. McBratney et al. (2003)은 환경변량과 토양특성과의 관계를 아래와 같이 정립하였다.
S = ƒ(s, c, o, r, p, a, n) + E (1)
s는 조사지점에서의 토양특성, c는 기후관련인자, o는 식생인자, r은 지형특성인자, p는 모재관련 인자, a는 시간인자, n은 공간정보를 의미한다. 초장기의 DSM 기술은 환경변량과 토양특성의 상관을 이용해 직선회귀식으로 미 측정 지점의 탄소 함량을 예측해 내었다면 최근에는 Cubist나 Random forest와 같은 딥러닝 기술을 이용하여 예측력을 높이려는 시도가 이루어 지고 있다(Lamichhane et al., 2019). 국내 토양의 탄소 저장량 산정 관련 연구로 Hong et al. (2010)은 70 - 80년대 조사된 토양자료를 활용하여 농경지의 1 m 깊이의 평균 탄소함량을 6.77 kg·m-2 이라 하였고, Park et al. (2018)은 조사된 농경지의 탄소 평균값을 면적에 곱해서 전국 토양의 탄소 저장량이 386 megaton이 된다고 하였다. 이러한 연구들은 오래된 과거의 토양조사자료를 이용하여 현재의 저장량을 반영할 수 없고 환경 변량을 이용하지 않아 미예측 지점의 탄소 함량 예측에 과학적 근거가 부족하다. 탄소 저장량을 산정하려면 깊이별 토양의 탄소 분석결과, 용적밀도, 모래, 미사, 점토와 같은 자료가 필요하지만 깊이별 데이터를 전국적으로 구축하는데 오랜 시간이 필요하다는 한계가 있다.
따라서, 본 연구에서는 DSM 테크닉을 이용하여 우리나라 전라도 지역의 탄소 분포지도를 작성하고 30 cm 깊이까지의 토양탄소 저장량을 산정하고자 하였다.
Materials and Methods
Soil sampling and analysis
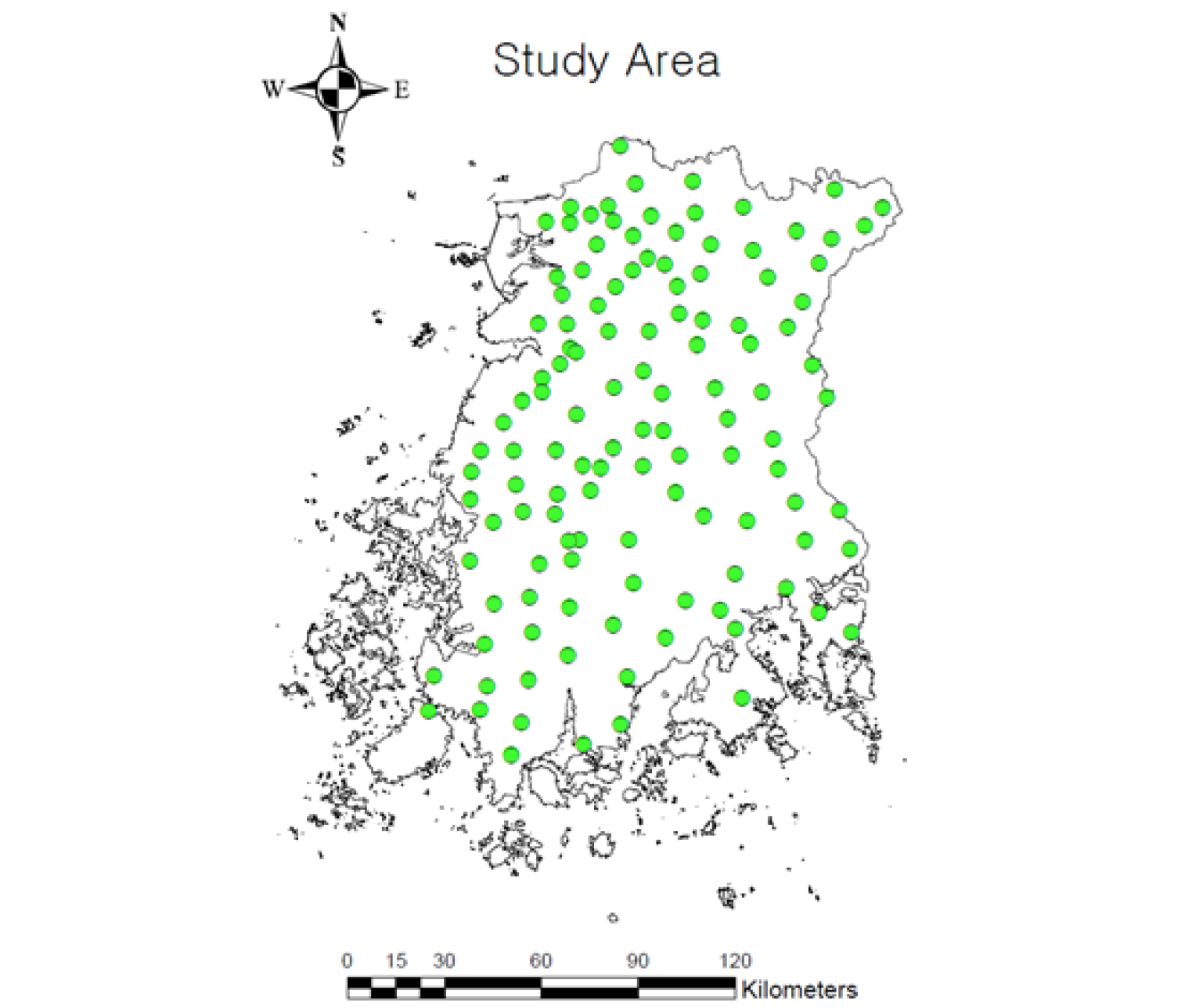
전라도는 대한민국 서남부에 위치하고 면적은 20,915 km2이며 서쪽으로는 해안과 평야지대인 반면 동쪽은 산악지역을 형성하고 있다. 탄소 저장량 산정을 위해 2020년 4월부터 6월까지 공간적 분포를 고려하여 총 130 지점에서 10 cm 간격으로 3개 층위(0 - 10, 10 - 20, 20 - 30 cm)의 시료를 special gauge augur를 이용하여 채취하였다(Fig. 1). 토양 시료는 풍건하여 2 mm 체를 이용해 자갈(> 2 mm)을 분리한후 총 탄소는 C/N analyzer (Vario Max CNS, Elementar, Langenselbold, Germany)로, 용적밀도와 토성은 농촌진흥청 토양 및 식물체 분석법(NIAST, 2000)에 준하여 각각 코어법과 비중계법(Gee and Bauder, 1986)을 이용하여 분석하였다.
Environmental covariate
탄소저장량 예측을 위한 회귀모델의 공변량(covariate)으로 쓰이는 환경변량은 scorpan model (McBratney et al., 2003) 모델을 기초로 수집하였다. 기상청(Korea Meteorological Administration, KMA)에서 최근 10년간의 평균 기온(average temperature, AvTemp)과 평균 강수량(precipitation) 및 연평균기온차(temperature range, TempRange)를 기후 변량(C factor)으로 사용하였다. 지형 변량은 수치표고모형(digital elevation model, DEM)을 다운로드(NGII, 2020)하고 SAGA GIS software (https://sourceforge.net/projects/saga-gis/)를 이용하여 고도(elevation), 지형습윤지수(topographic wetness index, TWI), 지형험상지수(terrain ruggedness index, TRI), 총 일사량(total insolation, TI), 경사(slope) 변량으로 추출하였다. 식생변량(O factor)은 구글 어스를 이용해 modis 위성 영상의 정규식생지수(normalised difference vegetation index, NDVI)를 연단위로 다운받아 중첩하여 사용하였고 모재특성 변량(P factor)은 토성분석을 통해 얻은 모래(sand), 미사(silt), 점토(clay)의 분석결과를 ordinary kriging 하여 이용하였다. 위의 변량들은 QGIS software (https://www.qgis.org/ko/site/)를 사용하여 좌표계(coordination system)을 일치시켜 Fig. 2에 나타내었다.
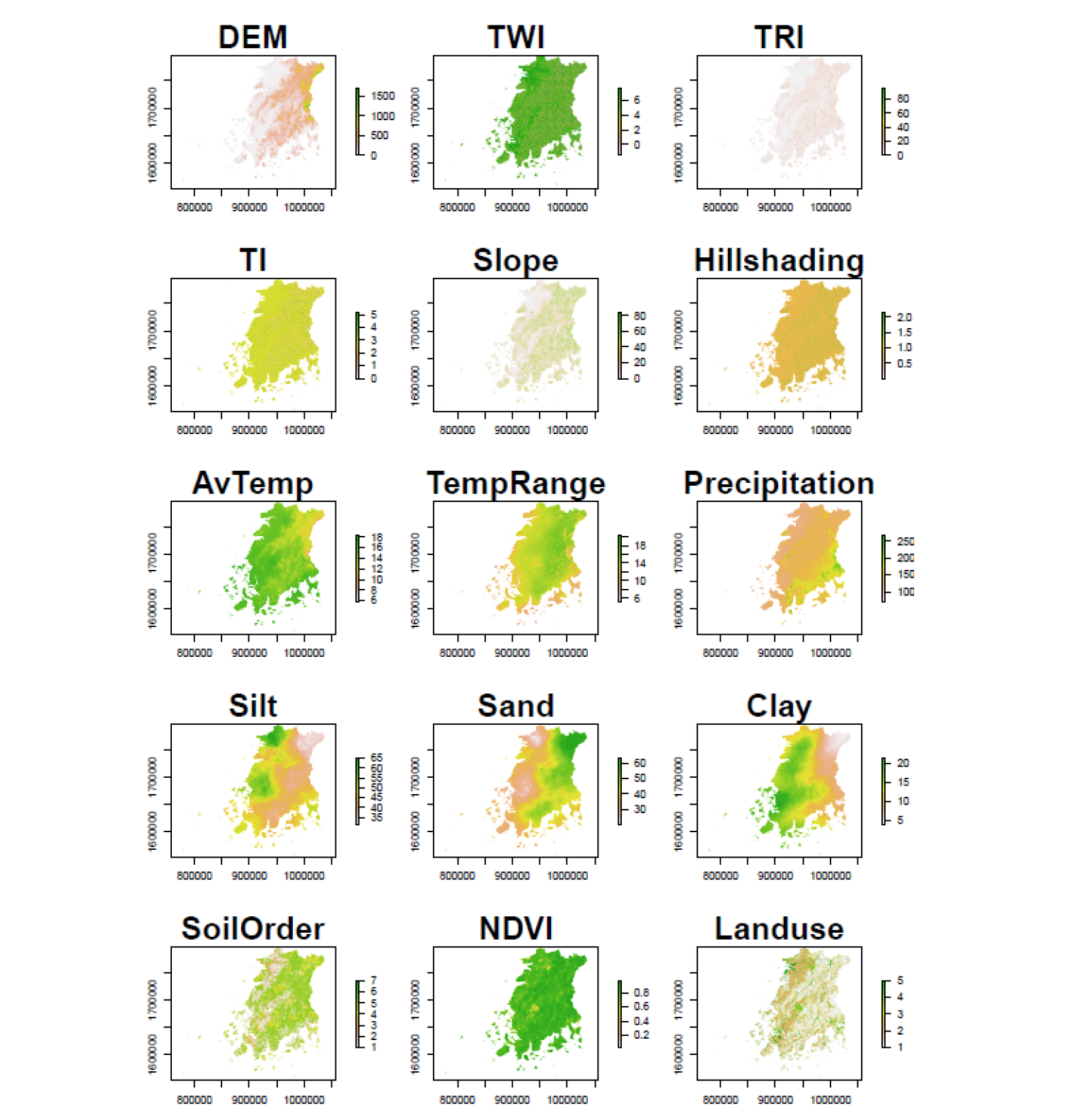
Fig. 2. Environmental covariate maps for prediction of soil carbon stock. DEM, digital elevation model (m); TWI, topographic wetness index; TRI, terrain ruggedness index; TI, total insolation; TempRange, temperature range (℃); NDVI, normalised difference vegetation index; AvTemp, average temperature (℃).
Calculation soil carbon density and total carbon stock
Carbon density는 단위면적당 탄소 함량으로 표시되는데 용적밀도와 자갈함량을 고려하여 계산하였다.
Carbon density (kg 〮 C 〮 m- 2) = 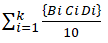 (1-Gi) (2)
(1-Gi) (2)
식에서 Bi 는 용적밀도(g·cm-3), Ci 는 탄소농도(%), Di 는 토양두께(cm), Gi 는 자갈함량(%)을 의미한다. 총 탄소 저장량(total carbon stock)은 carbon density에 흙토람(RDA, 2020)의 토양목별 면적을 추출하여 계산하였다.
Spatial modeling and validation
탄소의 공간분포 예측을 위해 cubist 모델을 사용하였다. Cubist 모델은 regression tree 모델 기반 data-mining 알고리즘을 이용하는 예측모델로 환경변량과 탄소 저장량과의 공간적 상관성을 이용하여 예측한다(Adhikari et al., 2014; Minasny and McBratney, 2016). 전체 데이터를 70% 와 30%로 나누어 calibration과 validation을 수행하였으며 통계적 파라메터인 R2, MAE, RMSE를 이용하여 예측 모델을 검증하였다. R2은 예측값과 관측값 사이의 회귀에 결정 계수이며, MAE는 the mean error the absolute prediction error이고 RMSE는 root mean square error이다.
R2 = 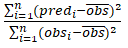 (3)
(3)
MAE = 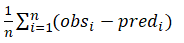 (4)
(4)
RMSE = 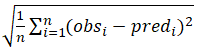 (5)
(5)
여기서 predi와 obsi는 측정지점에서의 탄소 저장량의 예측된 값과 실측값이고 n은 샘플의 개수를 의미한다.
Results and Discussion
Bulk density, carbon content, gravel and soil texture
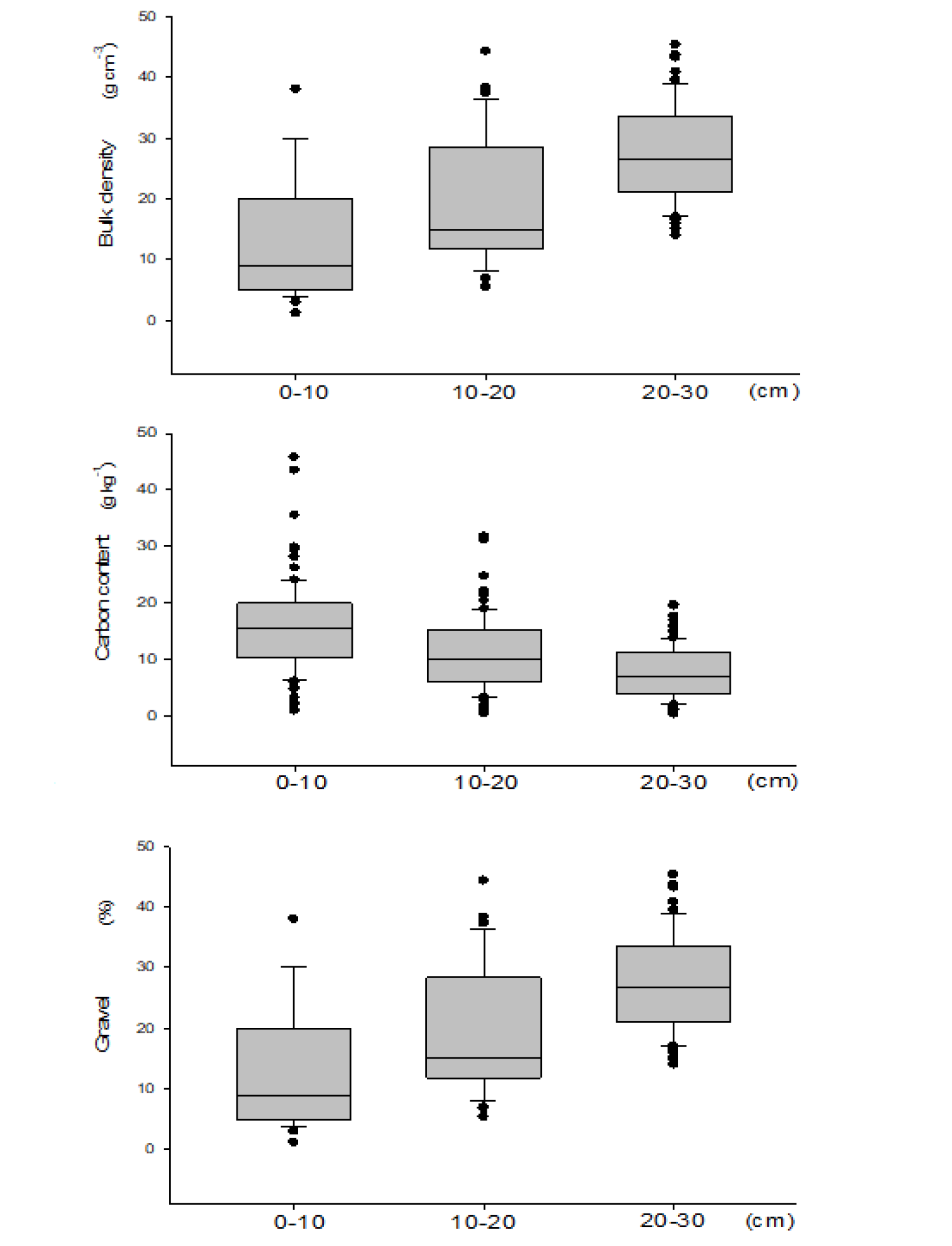
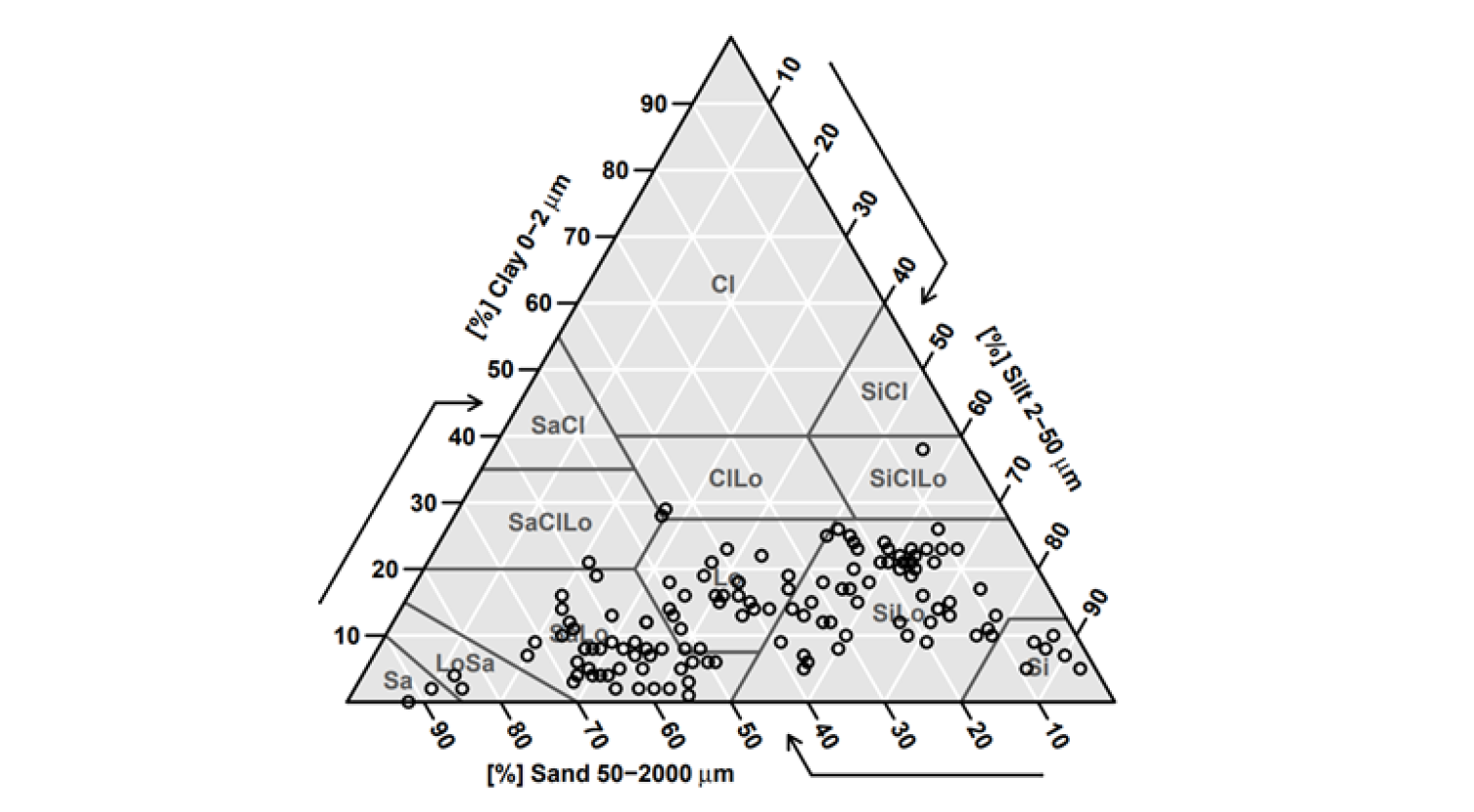
전라도 농경지 토양의 깊이별 평균 용적밀도는 0 - 10 cm 깊이에서 1.27 g·cm-3으로 가장 낮았고 20 - 30 cm에서 1.38 g·cm-3 로 가장 높아 층위가 깊어질수록 용적밀도가 증가하였다(Fig. 3). 반면 탄소 함량은 0 - 10, 10 - 20, 20 - 30 cm 깊이에서 각각 15.7, 10.9, 7.6 g·kg-1 이었으며 아래층위로 갈수록 값이 줄어 드는 경향을 보였다. 전체 토양 시료 중 자갈의 부피비율은 13.3% (0 - 10 cm), 19.2% (10 - 20 cm), 27.9% (20 - 30 cm)로 토양 깊이가 깊어질수록 증가하였다. 토성분석 USDA 기준의 삼각도표를 이용하였을 때 점토 함량이 40% 미만, 미사 함량은 60% 초과하는 토양만 존재하는 반면 모래함량은 3 - 92%까지 고른 분포를 보였다. 미사질 양토(n = 47)가 가장 많았고 사양토(n = 36), 양토(n = 25), 양질사토(n = 6) 등의 순으로 분포하였다(Fig. 4).
Spatial model performance
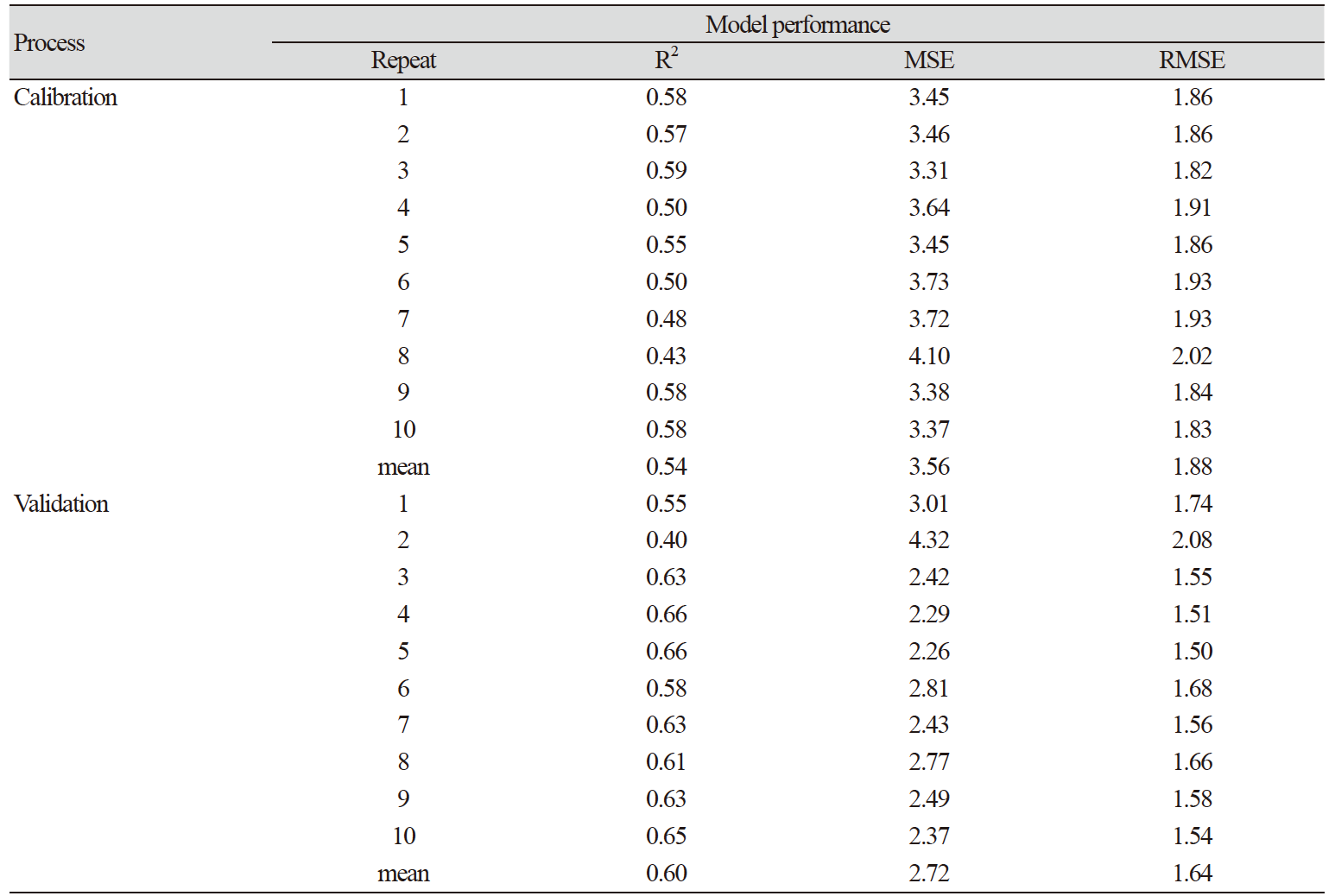
Table 1은 Cubist 모델의 탄소함량에 대한 공간예측 능력을 검증(validation) 하기 위하여 10회 반복수행한 결과이다. 70% 데이터를 무작위로 추출해서 모델을 calibration을 실시한 최종모델의 결정계수(R2)값은 0.54, MSE 3.56, RMSE 1.88이었다. 나머지 30% 데이터로 실시한 모델 검증(validation) 결과는 R2, MSE, RMSE가 각각 0.6, 2.72, 1.6으로 나타났다. Cubist 모델을 이용한 국외 사례에서 살펴 보면 모델 검증을 통해 얻은 결정계수(R2) 값이 Florinsky et al. (2002)은 0.37, Bui et al. (2009)은 0.41, Malone et al. (2014)은 0.44, 그리고 Kumar et al. (2012)는 0.36으로 보고하였는데 이에 비해 본 연구의 결과가 더 높은 결정계수 값을 보였다. 환경변량들이 탄소 예측에 관여하는 정도는 상대적 사용률(%)로 표시하는데, 종속변수인 탄소 저장량을 예측할 때 회귀식에 사용되는 변량의 빈도를 나타낸다. 모델 식 조건으로 사용된 환경변량은 점토함량(clay), 수치표고모형(DEM), 평균강수량(precipitation)과 평균기온범위(TempRange) 였고 모델에 사용된 사용률을 살펴보면 점토함량(clay)과 지형습윤지수(TWI)가 가장 높았고, 평균강수량(precipitation), 식생지수(NDVI)와 수치표고모형(DEM)이 60% 이상, 미사함량(silt)와 모래함량(sand) 순으로 사용된 것으로 분석되었다(Table 2).
Table 1. Cubist model calibration and validation results in predicting carbon stocks (0 - 30 cm)
|
|
MSE, mean square error; RMSE, root mean square error. |

Total soil carbon stock
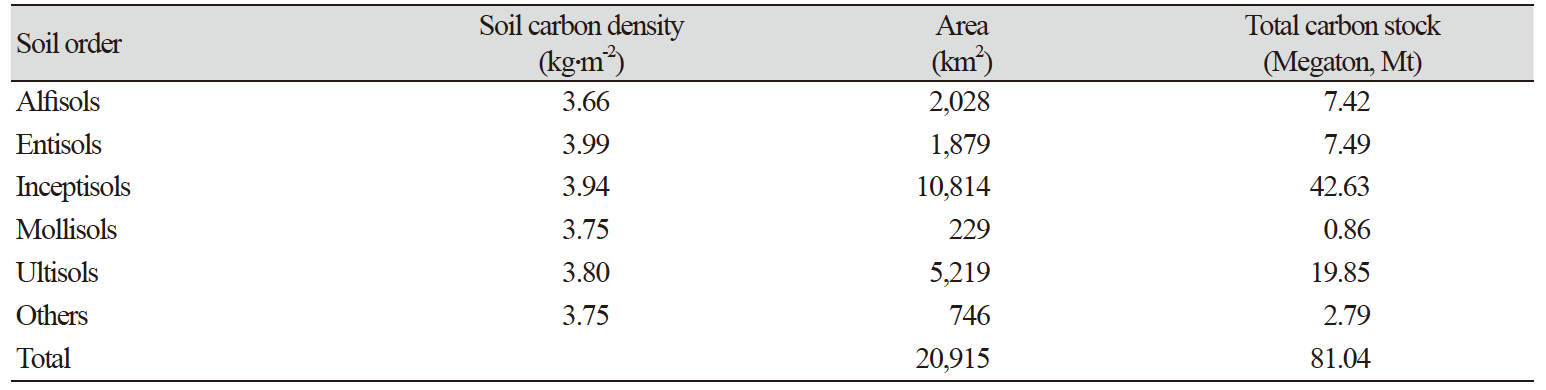
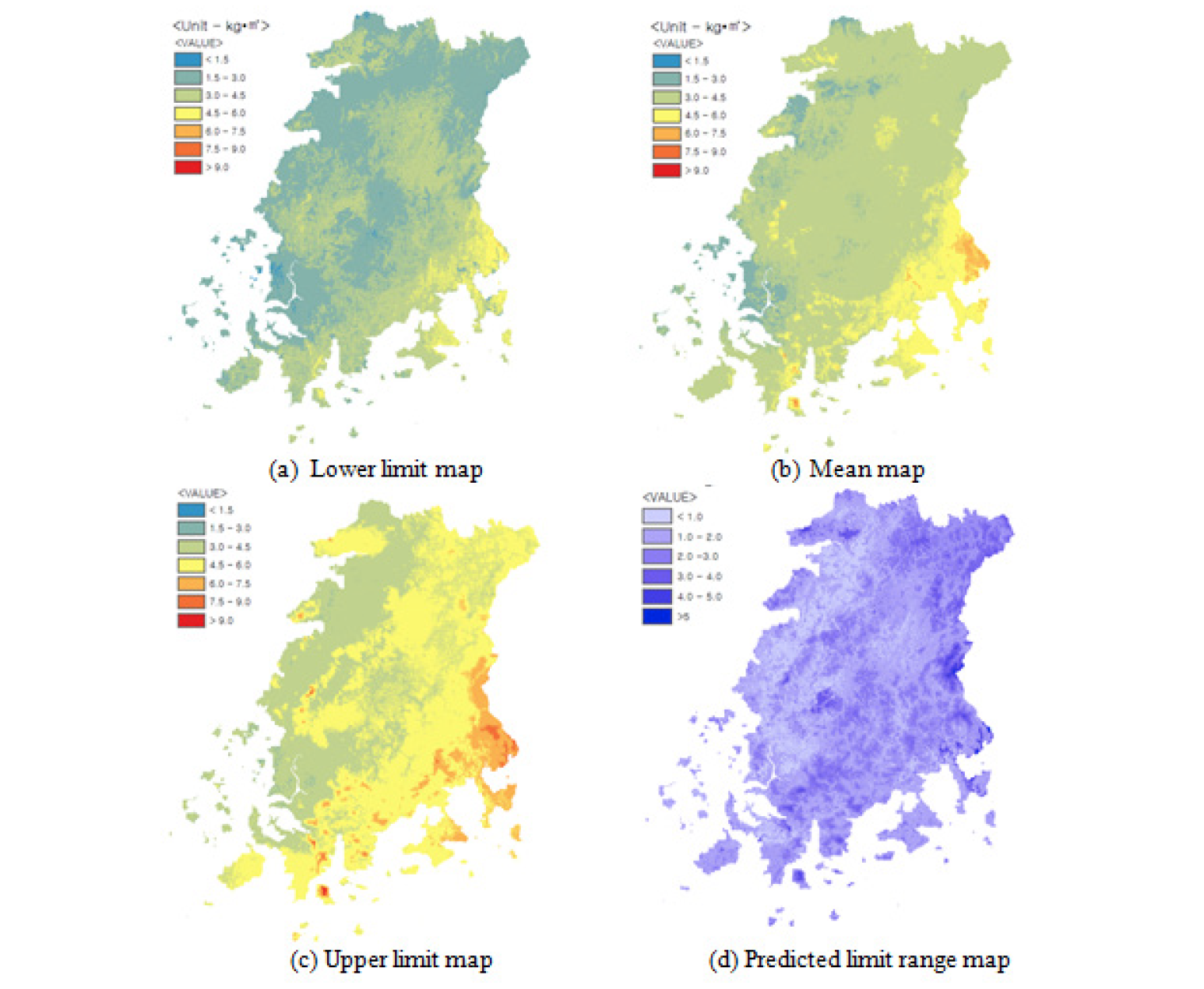
Cubist 모델이 예측한 토양(0 - 30 cm)의 탄소 저장량은 평균 3.88 kg·m-2였으며 최솟값은 1.92 kg·m-2, 최댓값은 8.01 kg·m-2이었다(Table 3). 예측의 불확도는 90% 유의수준에서 하한값(lower limit)과 상한값(upper limit)으로 나타내는데 그 평균은 각각 3.02 kg·m-2과 4.74 kg·m-2였으며 그 평균차는 1.72 kg·m-2로 계산되었다. 탄소 저장량의 공간적 분포는 전반적으로 전라도의 동남쪽 지역에 탄소 저장량이 높은 것을 확인할 수 있으며 반면에 서쪽 해안가 지역이 상대적으로 탄소 저장량이 낮았다(Fig. 5). Table 4는 흙토람의 토양도를 이용한 토양목(soil order)별 분포면적과 탄소 저장량을 보여준다. 전라도에는 inceptisols, ultisols, alfisols, entisols, mollisols의 토양목이 분포하였으며 개간 사업 등으로 아직 분류되지 않은 토양(others)이 존재했다. 토양목별 carbon density는 3.66 - 3.99 kg·m-2까지 분포하였으며 전라도 지역의 총 토양 탄소 저장량은 81.04 megaton (0 - 30 cm soil depth)으로 계산되어 Park et al. (2018)이 계산한 전국 토양탄소 저장량 386 megaton 과 비교해 약 21%에 해당되는 양을 가진 것으로 분석되었다.

Conclusion
본 연구는 전라도지역의 토양탄소 저장량을 산정하고 공간적 분포를 확인하기 위해 디지털 토양맵핑(DSM) 테크닉을 이용하였다. Cubist 모델을 이용해 탄소 함량을 예측했을 때 회귀식에 주로 이용된 환경 변량은 점토함량(clay), 지형습윤지수(TWI), 수치표고모형(DEM) 이었으며 평균 3.88 kg·m-2의 carbon density 가지고 있는 것으로 분석되었다. 모델의 퍼포먼스를 나타내는 결정계수(R2)값은 0.6으로 외국 사례에 비해 상대적으로 높은 예측력을 보였다. 공간적인 분포는 전라도의 동남쪽이 탄소 함량이 높은 반면 서쪽 해안가가 낮게 나타났으며 전라도 지역의 0 - 30 cm 깊이에서 총 토양 탄소 저장량은 약 81 megaton으로 예측되었다.
디지털 맵핑 기술을 이용해 우리나라 전체의 탄소저장량을 산정하려고 한다면 우선 전국적인 토양 깊이별 물리 화학성 데이터가 필요하다. 과거 토양 정밀 조사 사업(RDA, 2011)이 이루어진 이후에는 필요 조건을 충족하는 토양자료가 전무한 실정이다. 본 연구에서는 전라도 지역에 한하였지만 공간분포를 고려하여 깊이별로 토양을 샘플링하고 탄소 저장량 산정에 필요한 데이터를 조사하였다는 점에서 전국단위 토양 자료를 구축할 초석이 될 것이라 사료된다.
본 연구에서 디지털 토양 맵핑 기술을 이용했을 때 토양생성에 관여하는 환경 인자들과 상관을 이용해 미 조사지점의 탄소함량을 통계적으로 예측해 낼 수 있었다. 향후 토양 데이터가 축적되고 다양한 모델 알고리즘을 적용하면 디지털 토양 맵핑 기술은 국가 단위의 토양탄소 저장량 산정 뿐만 아니라 다양한 토양 특성정보를 과학적으로 예측하는데 유용할 것으로 판단된다.



