
Introduction
다른 농산물과 마찬가지로 과채류 역시 시장 개방 및 기후 변화에 따라 국내 시장에 공급되는 품목이 다양해지고 있다. 또한, 지속적인 시설원예 산업의 성장과 함께 최근 스마트팜 확산으로 일부 품목에 대해서는 연중 안정적인 생산이 가능해지는 등 과채류 공급 측면에서 많은 변화가 이루어지고 있다. 수요측면에서는 1인 가구 비율 증가, 더욱 심화되는 저출산·고령화 사회, 소득 구조 변화 등의 인구사회구조와 경제여건의 변화로 농식품에 대한 소비구조의 변화를 유도하고 있다. 친환경 및 유기농 농산물 등 농식품의 안전성과 건강 뿐만 아니라 편리성과 다양성 추구 등 소비자들의 선호 역시 복잡하고 다양화되고 있다. 실제로 통계청에 따르면 1인당 월별 과일 지출액은 실질가격 기준으로 1990년 9,199원에서 2018년에는 17,749원으로 약 2배 정도 증가한 것으로 나타났다. 한편 동일한 기간 동안 곡물에 대한 소비는 약 30% 감소한 것으로 보아 한국 소비자의 농식품에 대한 소비 성향이 변화하고 있는 것으로 판단된다(Park and Kwon, 2020). 과일 및 과채류 중에서도 과거 대비 사과, 감귤, 딸기, 바나나에 대한 지출액은 증가하였으나, 포도, 감, 참외, 수박은 지출액이 감소한 것으로 나타나 현재 과일 품목 내에서도 소비 트랜드는 꾸준히 변화하고 있는 것으로 분석되고 있다(Park et al., 2017).
이처럼 사회경제적 환경의 변화와 소비 트렌드가 달라지면서 과일 및 과채류의 수요가 어떻게 변화되는지, 소비지출액이나 그러한 소비를 결정하는 변수들이 무엇인지 분석하려는 연구가 꾸준히 시도되고 있다. 많은 연구들이 분석 대상 과일이나 과채류의 특성을 고려하여 공급과 수요의 계절성을 고려하였다. Lee and Choi (1999))은 통계청의 「도시가계조사」의 월별 지출액 자료와 소비자물가지수를 이용하여 과일류 및 과채류를 소비시기를 계절별로 구분한 후 선형화된 준이상수요체계(LA/AIDS)모형을 이용하여 수요모형을 추정하였다. Noh et al. (2012)는 수입산 과일과 국내산 과일의 경합 시기를 고려하여 과일 수요체계를 로테르담 모형을 이용하여 자체 및 교차 가격과 지출 탄력성을 추정하였다. 이 외에도 Kim et al. (2015), Kim et al. (2016)는 각 계절 더미 변수와 주기함수를 추가한 모형으로 국내산 및 수입산 주요 과일에 대한 수요체계를 분석하였다. 이들 연구는 과일이나 과채류가 갖는 계절성을 반영하기 위해 특정 품목과 기간으로 자료를 절단하여 수요함수를 추정하였다.
반면, 각 소비자나 가구가 가지고 있는 사회경제적 특성이 과일 및 과채류 소비에 어떤 영향을 미치는지를 분석하기 위해서 소비자 패널을 이용한 수요 분석 역시 활발하게 이루어지고 있다. Mun and Chang (2019)은 2010 - 2017년 동안 구축된 농촌진흥청의 불균형 소비자 패널 자료를 이용하여 이차형 준이상수요체계(QUAIDS) 모형을 이용하여 분석하였으며, Park and Kwon (2020)은 농촌진흥청의 650가구의 농식품 소비자 패널 자료 중 2017년 1월부터 2018년 11월 자료를 이용하여 가격 변수의 내생성과 집계 상의 오류 가능성을 반영한 MDCEV모형을 이용한 농식품의 소비 트랜드 변화에 따른 과일류에 대한 소비를 분석하였다. 이러한 대부분의 과일 및 과채류 소비분석 연구들은 수요시스템 모형을 활용하여 소비에 대한 분석을 실시하였다. 이들 대부분의 연구는 품목의 제철에 소비가 이루어지며, 제철의 경우의 소비는 분석에서 제외하여 분석을 실시하였다.
본 연구 역시 기존연구들처럼 소비자 패널 자료를 이용해 가구별 특성이 과채류 소비지출액에 미치는 영향을 분석하고자 한다. 그러나, 이 연구는 분석방법에 있어 기존 연구와 차별화를 시도한다. 기존 연구들은 수요체계 방정식 추정을 통해 가구 특성이 소비지출액 결정에 영향을 미친다고 가정하고 분석하였다. 컴퓨터의 자료 처리 능력이 지속적으로 향상되고 최근 들어 빅데이터의 활용과 인공지능에 대한 관심이 높아짐에 따라 인공신경망(artificial neural network) 모형을 이용하는 연구가 다수 이루어지고 있다. 인공신경망 모형은 다른 모형에 비해 분석에 필요한 가정이 적고, 유연하기 때문에 이용자료들에 대해 다양한 분석이 가능하여 여러 분야에서 연구가 많이 시도되었다(Terzi, 2007; Pao, 2008; Kaya et al., 2012; Cho and Byeon, 2015; Galeshchuk, 2016; Byeon, 2017; Lee and Yang, 2017; Jeong, 2018, Le et al., 2018; Lee et al., 2018). 본 연구에서는 농촌진흥청의 소비자패널자료를 이용해 주요 시설 과채류(딸기, 토마토, 파프리카)에 대해 패널모형과 인공신경망 모형을 적용하여 가구의 사회경제적 특성이 소비지출액에 미치는 영향을 추정하고, 이를 토대로 두 모형의 특정 조건의 구매 형태를 예측하여 실제 구입액을 비교함으로 분석결과의 정확도를 비교하고자 한다.
Materials and Methods
분석모형
본 연구는 인공신경망 모형의 우리나라 가구의 과채류 구매 결정요인을 파악하고 구매 예측력을 비교하기 위해서 먼저 패널모형인 고정효과모형(fixed effect model)과 확률효과모형(random effect model)을 이용하여 소비자 패널 자료를 분석하였다. 패널 자료를 일반 회귀모형 방법으로 추정하게 되면, 변수 사이의 내생성 문제(endogenous problem)로 인하여 과대추정(over-estimated)이 될 수 있다(Bell and Jones, 2015). 고정효과모형과 확률효과모형은 오차항의 형태에 따라 구분한다. 고정효과모형과 확률효과모형 중 추정의 타당성을 검증하는 방법으로 하우스만 검정(Hausman test)을 시행한다. 하우스만 검정의 귀무가설(H0)는 ‘상수항과 설명변수는 상관관계가 없음(Cov(Xi,tn,μt) = 0)’이며, 하우스만 검정의 귀무가설을 기각할 경우는 고정효과모형이 적합하며, 귀무가설을 기각하지 못할 경우 확률효과모형을 이용하여 분석하는 것이 적합하다(Min and Choi, 2010; Zhu et al., 2015).
먼저 소비자 가구 패널 자료는 시간의 흐름에 따라 가구의 과채류 구입과 이에 영향을 미치는 변수들을 분석하는 것이므로 식(1)과 같이 시간을 고려한 방정식으로 표현할 수 있다.
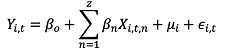 (1)
(1)
식(1)의 Yi, t은 각 패널의 특정 시점의 과채류 구입액을 의미하며, Xi, t, n는 계절, 구입처, 소득 등 패널의 구입액에 미치는 요소를 의미한다. 또한 μi은 관찰되지 않는 시간 불변 오차항을 의미하며, εi, t는 순수 오차항을 의미한다. 이러한 패널 모형에서는 오차항과 독립변수 사이의 상관관계를 고려하지 않고 일반 회귀분석 OLS (ordinary least square)를 이용하여 방정식을 추정하면, 편의가 발생하는 문제가 발생한다.
횡단면 자료에서 내생성을 문제를 해결하기 위하여 고정효과 모델을 사용하여 모형의 관측되지 않는 변수 μi를 제거할 수 있다. 고정효과 모형은 μi를 확률변수가 아닌 추정해야 할 모수로 간주하여 추정한다.
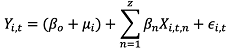 (2)
(2)
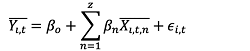 (3)
(3)
식(2)는 식(1)을 변형한 식이며, (βo + μi)는 패널 개체별로 달라진다. 식(3)는 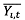 는
는 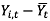 를 의미하며, 이는 패널의 구입액을 각 시점의 전체 평균 구입액을 빼준 금액을 의미하며,
를 의미하며, 이는 패널의 구입액을 각 시점의 전체 평균 구입액을 빼준 금액을 의미하며, 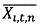 는 와 동일한 방법으로 구하여 사용한다. 식(3)는 기존의 방정식에서 내생성 문제를 내포하는 개인의 관측되지 않는 속성 μi을 제거할 수 있다. 따라서 βn의 고정효과 추정 계수는 εi, t이 모든 시점에서 각각의 독립변수와 상관관계가 없는 불편추정량의 성질을 갖는다.
는 와 동일한 방법으로 구하여 사용한다. 식(3)는 기존의 방정식에서 내생성 문제를 내포하는 개인의 관측되지 않는 속성 μi을 제거할 수 있다. 따라서 βn의 고정효과 추정 계수는 εi, t이 모든 시점에서 각각의 독립변수와 상관관계가 없는 불편추정량의 성질을 갖는다.
고정효과모형과 비교하는 인공신경망 모형은 인간의 두뇌에서 착안하여, 수학적으로 모방하여 고안한 방법으로 최근 컴퓨터 성능 향상 및 인공지능, 빅데이터에 관한 관심이 높아짐에 따라 주목받고 있는 모형이다. 인공신경망은 입력 데이터로부터 반복적인 학습 과정을 통해 데이터에 숨어있는 패턴을 찾는 데이터 마이닝 모델링 기법으로, 복잡한 구조를 보이는 자료에서 예측 문제를 해결하기 위해 사용하는 비선형적 모형(nonlinear models)이다. 인공신경망은 기존의 전통적인 계량 분석과 달리 자유도(degree of freedom)에 제약을 받지 않으며, 다중 공선성(multi-collinearity)문제로부터 자유로울 수 있어서 다양한 분석이 가능하다는 장점이 있다(Kim et al., 2017).
본 연구에서는 인공신경망 중 가장 널리 사용되는 모형인 오류 역전파 알고리즘(error back-propagation algorithm)을 이용한 다층 퍼셉트론 모형(multilayer perceptron)을 이용하였다. 다층 퍼셉트론 모형은 입력층(input layer), 은닉층(hidden layer), 출력층(output layer)로 구성되어 있다). 각각의 층은 세포와 같은 노드(node)로 구성되어 있다.2) 입력층을 통해 입력된 정보(x1, t, x2, t, x3, t, ⋯, xp, t)는 아래와 같은 식(4), (5)에 따라 계산 후 출력층으로 결과를 도출한다.
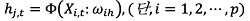 (4)
(4)
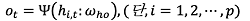 (5)
(5)
식(4)는 은닉층을 의미하며, 입력된 정보는 활성화 함수3)(Φ)에 의해 계산되어 출력층으로 전달할 중간값(h1, t, h2, t, ⋯, hq, t)이 된다. 식(4)에서 계산된 중간값은 또 다른 활성화 함수(Ψ)에 의해 가공되어 인공신경망에 의한 예측값 ot를 도출한다. 이때 각 식의 ωih와 ωho는 일반적 회귀모형의 추정된 모수와 같은 역할을 하는 가중치를 의미하며, 입력층과 은닉층의 정보는 각각 하나의 노드를 형성한다(Lee and Yang, 2017).
신경망 중 오류 역전파 알고리즘은 반복 과정에서 손실함수를 통해 계산한 오차를 감소시키기 위하여 ‘경사 하강법(gradient-descent method)’을 이용한다. 손실함수는 인공신경망 학습의 기준이 되며, 가장 많이 사용하는 손실함수는 평균 제곱 오차(mean squared error, MSE)가 있다(식(6)).
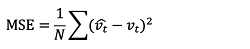 (6)
(6)
식(6)의 N은 예측한 수를 의미하며, 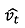 는 인공신경망을 통해 예측한 값을 의미한다. 또한 vt는 실제값으로 MSE는 오차 제곱의 평균이다. 인공신경망의 학습은 MSE가 감소하는 방향으로 가중치를 수정하여 반복 추정하여 정확도를 높이게 된다. 반복 추정을 실시할 때, 학습률(learning rate)를 통하여 과거의 오류를 반영하는데, 학습률은 이전의 오류 중 실제 오차 수정에 반영하는 비율을 의미한다.
는 인공신경망을 통해 예측한 값을 의미한다. 또한 vt는 실제값으로 MSE는 오차 제곱의 평균이다. 인공신경망의 학습은 MSE가 감소하는 방향으로 가중치를 수정하여 반복 추정하여 정확도를 높이게 된다. 반복 추정을 실시할 때, 학습률(learning rate)를 통하여 과거의 오류를 반영하는데, 학습률은 이전의 오류 중 실제 오차 수정에 반영하는 비율을 의미한다.
인공신경망 모형은 전체 분석자료를 두 구간으로 나누어 예측과 검증을 진행한다. 전체 분석자료의 일부를 이용하여 인공신경망을 학습시킨 후, 나머지 자료를 이용하여 학습의 정도를 판단하기 위한 검증을 실시한다. 전자에 이용하는 자료를 학습 집합(training set), 후자에 이용되는 자료를 검증 집합(validation set)이라고 하며, 각각을 7 : 3 혹은 8 : 2로 구성하는 것이 일반적이다(Kim and Won; 2018, Yu and Li; 2018).
학습을 마친 모형에 대한 정확도는 검증 집합의 자료를 이용하여 손실함수와 동일한 MSE를 이용하여 예측값과 실제값의 오차를 값을 계산한다. 이때 MSE가 낮을수록 정확한 예측을 한 것으로 평가할 수 있다. 한편 분석모형 간의 예측력을 비교하기 위한 통계적 유의성 검정은 Diebold and Mariano (1991)에 의해 고안된 DM 검정을 통해 실시하였다. DM검정의 귀무가설(Ho)은 ‘두 모형의 예측력에 차이가 없음’을 의미한다(식(7)).
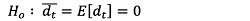 (7)
(7)
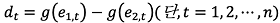 (8)
(8)
 (9)
(9)
식(8)의 dt는 모형 간 손실함수의 차이를 의미하며, 식(9)의 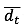 는 dt의 평균을 의미한다. 모형 사이의 손실 함수 차이(dt)의 분산(
는 dt의 평균을 의미한다. 모형 사이의 손실 함수 차이(dt)의 분산(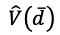 )은 다음의 식(10)로 나타낼 수 있으며, 식(10)의 분산에서 추정된 DM 통계량은 식(11)과 같이 나타낸다(Diebold and Mariano, 1991). 식(10)의 γk는 모형의 손실 함수의 차이 dt의 k기 시차 간의 자기공분산을 나타내며, 추정된 를 이용하여 식(11)의 DM검정의 통계량을 추정할 수 있다.
)은 다음의 식(10)로 나타낼 수 있으며, 식(10)의 분산에서 추정된 DM 통계량은 식(11)과 같이 나타낸다(Diebold and Mariano, 1991). 식(10)의 γk는 모형의 손실 함수의 차이 dt의 k기 시차 간의 자기공분산을 나타내며, 추정된 를 이용하여 식(11)의 DM검정의 통계량을 추정할 수 있다.
 (10)
(10)
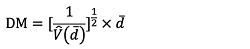 (11)
(11)
본 연구에서 소비자 패널의 주요 시설 과채류의 구매 결정요인을 분석하고 구매 예측력을 분석하기 위하여 인공신경망의 각 층의 노드 수, 은닉층의 수, 데이터 표준화 방식은 선행연구를 참고하였다. 일반적으로 입력층과 출력층의 노드 수는 각 입력변수와 출력변수의 수로 구성한다. 입력 노드의 수는 계절, 구매처 등 가구의 과채류 구입액에 영향을 미치는 변수로 하였으며, 출력변수는 예측하고자 하는 구입액으로 하였다. 은닉층의 노드는 시행착오를 통해 예측력이 가장 높은 경우를 예측모형으로 적용하는 것이 일반적이다(Yun et al., 2016; Lee and Yang, 2017). 또한, 인공신경망을 이용하여 예측할 경우 출력변수 자료를 0과 1 사이의 값으로 표준화시켰을 때 예측력이 향상되는 것으로 알려져 있다. 이에 따라 다음의 식(12)과 같이 구입액을 표준화하여 예측을 실시하였다(Moon et al., 2008; Yun et al., 2016; Kim and Won, 2018; Yu and Li, 2018).
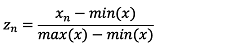 (12)
(12)
식(12)의 zn는 표준화된 구입액을 의미하며, xn는 1회 구입액을 의미한다. 표준화 방법은 1회 구입액과 1회 구입액의 최솟값의 차를 1회 구입액의 최댓값과 최솟값의 차로 나눈 값으로 계산한다.
분석자료
본 연구는 우리나라 가구의 딸기, 토마토(완숙/방울), 파프리카 등 과채류의 구매 결정요인을 분석하고 소비지출액에 대한 모형의 예측력을 비교하기 위하여 농촌진흥청의 농식품 소비자 패널 자료 중 2010년 1월부터 2018년 11월까지 일별 자료를 이용하였다4). 농촌진흥청의 농식품 소비자 패널 자료는 상품명, 구입처, 구입액, 중량, 브랜드, 원산지, 구입 시 결제 수단 등 구매행위에 대한 정보와 소비자의 나이, 직업, 거주지, 가족 구성원의 정보 등 인구통계학적 정보를 조사하고 있다. 해당 조사는 2010년 조사 초기 수도권을 중심으로 1,000가구를 대상으로 조사하였으나, 2018년 기준 전국 1,640가구를 대상으로 한다. 따라서 농촌진흥청의 농식품 소비자 패널 자료는 불균형(unbalanced) 패널 자료의 형태를 보인다.
본 연구는 패널 가구의 과채류 구매 결정요인 분석과 특정 조건에서 가구의 1회 구입액 예측이 목적이기 때문에, 조사된 소비자 패널의 1회 구입액을 사용하였다. 조사된 품목 구입액은 이상치(outlier)가 있는 것으로 판단되어, 총 2단계를 통해 이상치를 제거하였다. 먼저 Tukey (1977) 방법을 통해 이상치를 제거한 후, 품목별 최소 단위 금액 이하를 제거하여 이상치를 제거하였다5).
가구의 과채류 구입액에 영향을 미치는 요소를 계절, 구매 지역, 구입처 등 구매 행위에 대한 변수와 주 구입원의 연령, 가족 구성원 수, 직업(전업주부/취업주부), 소득 등 인구통계학적 변수, 그리고 패널이 농·식품 구매에 있어 중요하게 여기는 요소를 비용, 품질, 원산지, 안전성 등으로 구분하여 구매 결정요인에 대한 변수로써 사용하였다. 과채류 구매행위에 대한 변수와 함께, 인구통계학적 변수는 더미 변수(dummy variable)로 변환하여 사용하였으며, 농식품 구매 시 구매 고려요인(비용, 품질, 원산지, 안전성) 변수는 0과 1 사이의 값으로 네 변수의 합이 1이 되도록 하였다.
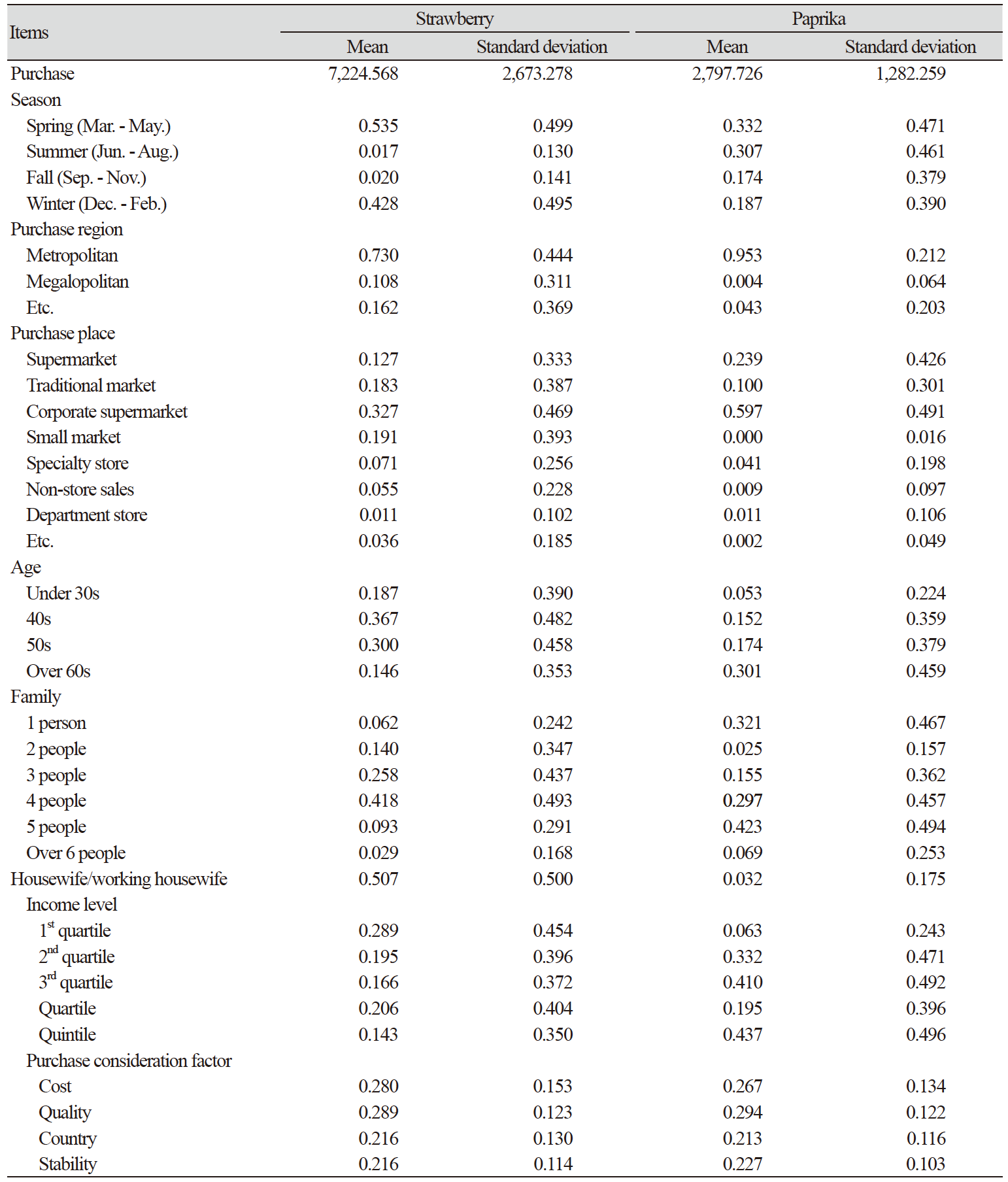
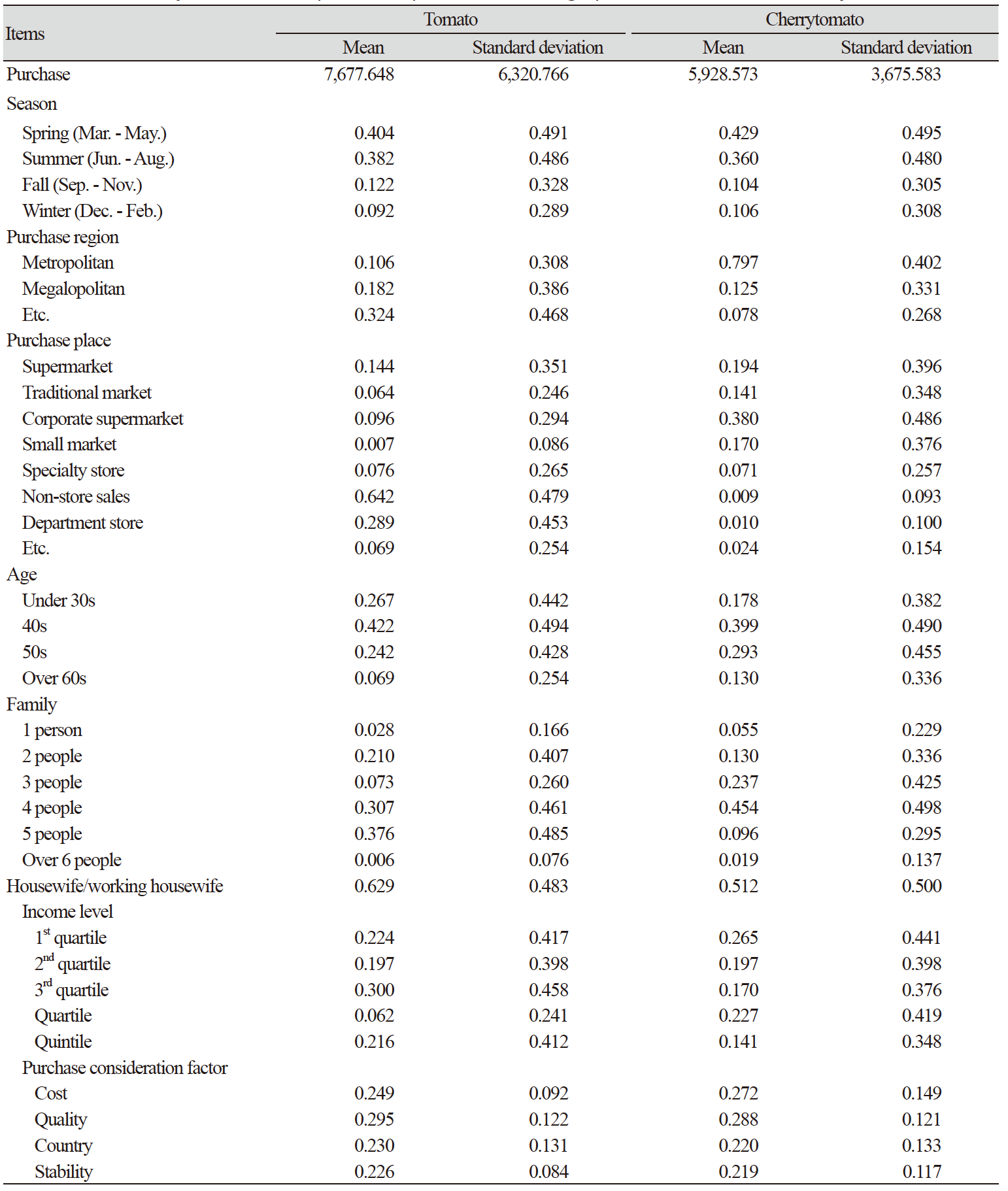
분석에 사용된 각 품목별 1회 구매행위에 대한 기초 통계량은 Table 1, 2와 같다. 1회 구매행위에서 구입액은 완숙토마토, 딸기, 방울토마토, 파프리카 순으로 높게 형성되어 있으며, 가격의 편차는 완숙 토마토, 방울토마토, 딸기, 파프리카 순으로 높은 것으로 확인되었다. 한편 계절 딸기는 봄(3 - 5월)과 겨울(12 - 1월)에 소비가 집중되어 있으며, 완숙 토마토와 방울토마토, 파프리카는 봄(3 - 5월)과 여름(6 - 9월)에 주로 소비되는 것으로 나타났다. 또한, 인구통계학적 변수인 주 구입원의 연령, 가족구성원수, 직업(전업주부/취업주부), 소득계층은 가구 특성 변수로 반영하였다.
Results and Discussion
본 연구는 두 모형 사이의 예측을 비교하는 것이기 때문에, 예측을 위해 사용된 자료와 검증에 필요한 자료를 구분하여 분석을 실시하였다. 인공신경망 모형의 예측 학습을 위한 자료(training set)과 실제 예측과 비교하는 검증 자료(test set)를 8 : 2로 구성하여 실시하였다. 분석의 통일성을 위하여 패널 회귀분석 역시 요인분석 자료와 예측 검증 자료를 8 : 2로 분할하여 분석을 실시하였다.
인공신경망 모형의 설정은 다음과 같이 진행하였다. 인공신경망 모형을 활용한 선행연구들을 참고하여, 반복횟수(epoch)는 최대 1,000으로 하였고, 학습률(learning rate)은 0.001로 설정하였다. Fig. 1은 딸기의 인공신경망 모형을 표현한 것으로 이와 동일한 방법으로 각 품목의 인공신경망 모형 은닉층 노드는 딸기 30개, 파프리카 24개, 완숙 토마토 32개, 방울토마토 31개로 구성하였다.

인공신경망의 경우 판별함수가 비선형적 관계를 갖기 때문에 독립변수와 종속변수 사이의 선형적 관계성을 직접적으로 해석하기 힘든 단점이 있다. 이를 극복하기 위하여 Garson (1991)은 가중치 분할법(weight partitioning method)을 제안하여, 독립변수와 종속변수 사이의 관계를 중요도(relative importance of contribution factor)로 평가할 수 있게 되었다. Garson (1991)의 가중치 분할법은 입력층과 은닉층 사이의 가중치(ωih)와 은닉층과 출력층 사이의 가중치(ωho)를 곱하여 절댓값을 취하여 Xij값을 구한다(식(13)). 그리고 각각의 노드에 대해서 Yij과 Si값을 식(14) - (16)와 같은 방식으로 계산한다. 마지막으로 각각의 독립변수의 상대적 중요도를 나타내는 식(16)의 Zi값을 통해 독립변수가 설명변수에 미치는 영향의 정도를 제시할 수 있다.
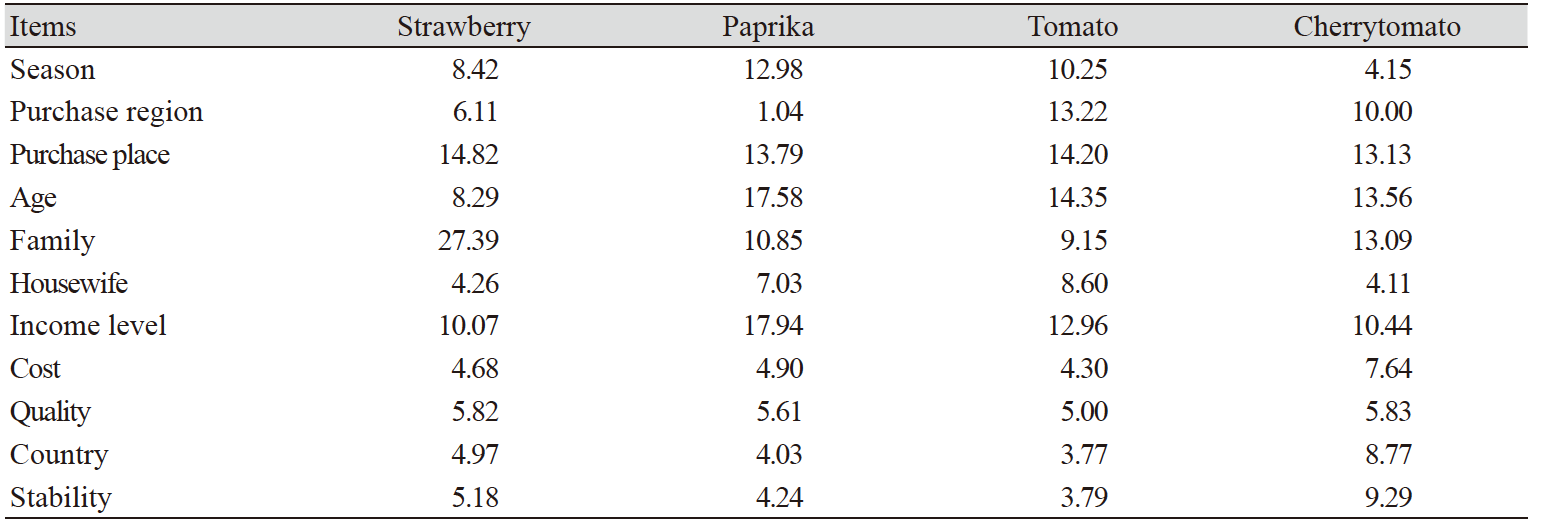
각 품목별 가중치를 이용하여 딸기, 완숙 토마토, 방울토마토, 파프리카에 대한 인공신경망 모형을 통해 분석한 상대적 중요도(Zi) 결과는 Table 3과 같다. 딸기의 경우, 가족 수의 상대적 중요도가 27.39%로 가구의 딸기 구입액에 가장 높은 영향을 준 것으로 나타났으며, 다음으로 구입처와 소득수준이 10 - 14%대의 높은 중요도를 갖는 것으로 나타났다. 한편 완숙토마토의 경우 주 구입원의 연령과 구입처, 구매 지역이 가구의 완숙토마토 구입액에 가장 높은 중요도를 가지는 것으로 나타났으며, 상대적으로 가격, 품질, 원산지, 안전성과 같은 구매 고려요소로 판단했던 변수들에 대한 영향력은 낮은 것으로 나타났다. 방울토마토의 경우, 연령대, 구입처, 가족수가 방울토마토 구입액에 영향을 미치는 것으로 나타났으며, 다음으로 소득, 지역, 가격순으로 영향을 미치는 것으로 분석되었다. 한편 파프리카는 소득과 연령의 중요도가 각각 17.94%와 17.58%로 가장 높은 영향을 미치는 것으로 나타났으며, 구입처, 계절, 가족구성원수 순으로 높은 영향력을 미치는 것으로 나타났다.
패널 회귀분석 모형은 고정효과모형과 확률효과모형이 있다. 고정효과모형과 확률효과모형 가운데 어느 것이 사용하는 자료 분석에 적합한지 판정하기 위해 하우스만 검정(Hausman test)을 실시하였다. Table 4는 하우스만 검정의 결과를 나타낸 것으로 딸기, 완숙토마토, 방울토마토, 파프리카 모든 품목에서 귀무가설(H0)을 기각하여, 확률효과모형보다 고정효과로 추정하는 것이 더 적합한 것으로 판단되었다.

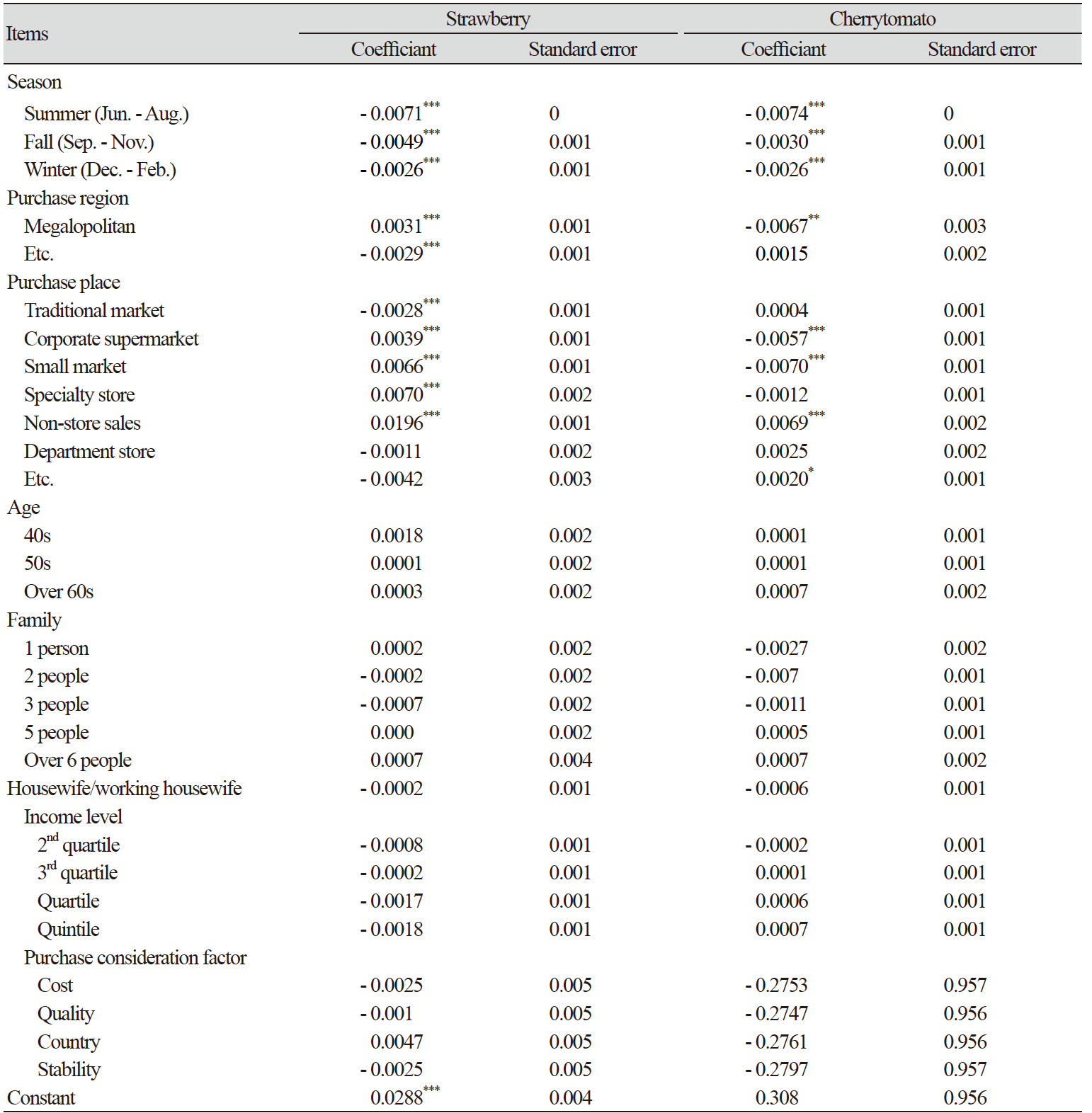
고정효과 모형을 이용하여 과채류 구매 결정요인을 분석한 결과는 품목별로 Table 5와 Table 6으로 나타났다. 우선 Table 5의 딸기는 계절, 구입처, 연령에 관한 변수에서 통계적으로 유의한 상관관계를 나타냈으며, 지역, 가족구성원수, 소득계층에서는 일부 설명변수에서 통계적으로 유의한 상관관계를 보였다. 딸기는 봄에 비해 여름에 구입액이 감소하고, 가을과 겨울에 구입액이 증가하는 것으로 나타났다. 특히, 가을에는 봄에 비해 구입액이 증가하는 요인으로는 전체 패널의 구입 횟수가 상대적으로 적으나, 딸기 가격이 높게 형성되어 이러한 결과를 보인 것으로 나타났다. 또한, 수도권에 비해 광역시와 기타 지역의 구입액이 높은 것으로 나타났다. 구입처의 경우 대형마트가 백화점을 제외한 다른 소매업태보다 구입액이 높은 것을 확인할 수 있었으며, 다른 연령층에 비해 30대 이하의 연령층에서 낮은 구입액을 보이는 것으로 나타났다. 파프리카의 고정효과 모형 추정 결과, 계절과 일부 지역 및 소매업태, 일부 연령에서 유의한 결과를 보였다. 파프리카의 경우, 봄철보다 가을과 겨울에 구매액이 높았으며, 여름은 봄에 비해 구매액이 낮게 형성된 것으로 나타났다. 수도권에 비해 광역시에서 높은 금액이 형성되어 있는 것으로 나타났다.
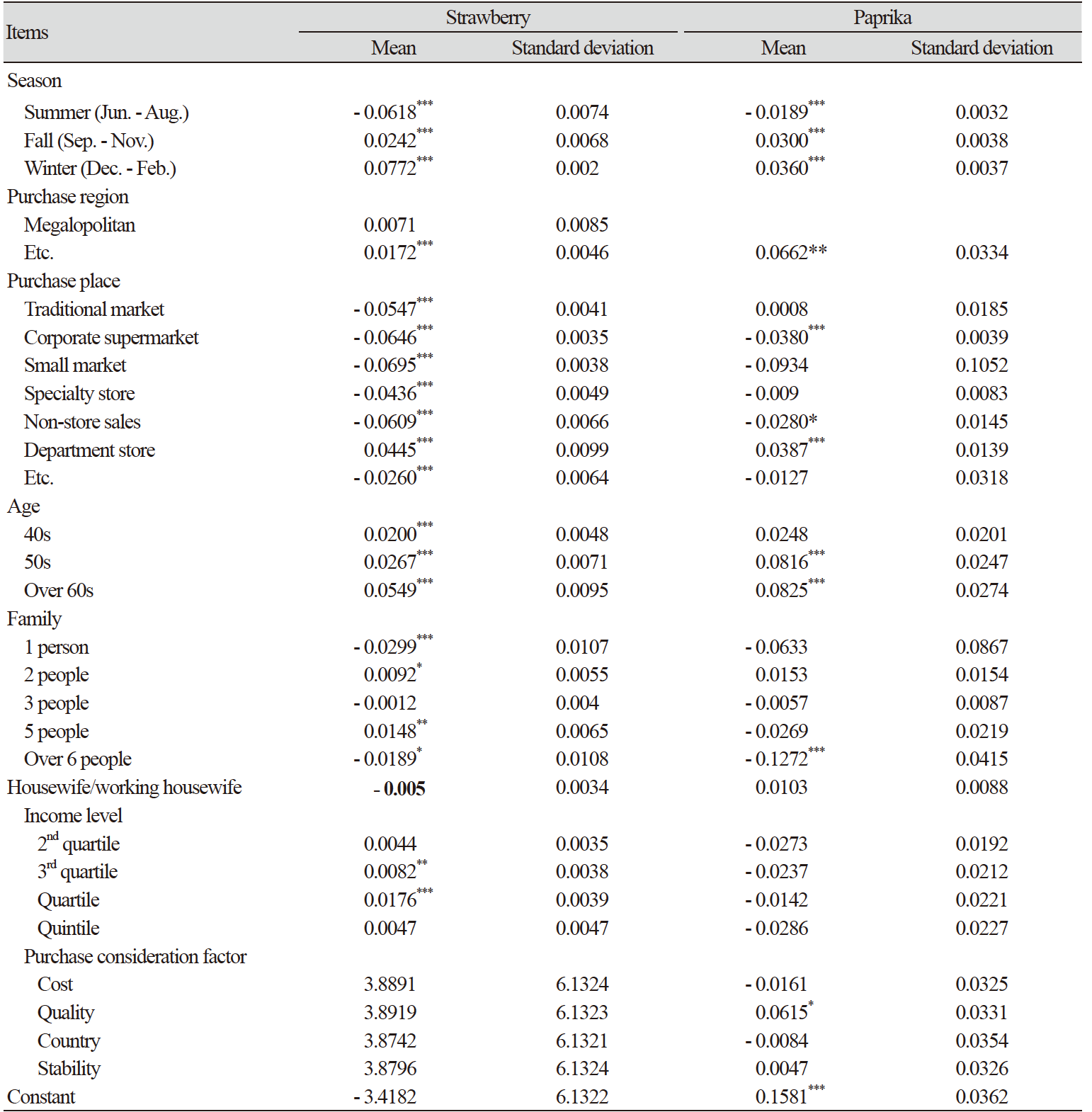
Table 6의 완숙 토마토의 고정효과 모형의 추정 결과, 계절과 구매 지역, 일부 구입처에서 통계적으로 유의한 상관관계를 보였다. 분석결과에 따르면 완숙 토마토의 구매액은 봄에 가장 높은 것으로 나타났으며, 구입 지역에서는 수도권에 비해 광역시는 구매액이 높은 것으로 나타났으며 기타 지역은 수도권에 비해 낮은 금액으로 구입액이 형성되어 있는 것으로 나타났다. 대형마트보다 전통시장에서의 구매액이 낮은 것으로 나타났으며, 기업형 슈퍼, 소형슈퍼, 전문점, 무점포 판매에서 대형마트보다 구매액이 높은 것으로 나타났다.
마지막으로 방울토마토의 고정효과 모형 추정 결과는 계절과 일부 소매업태에서 통계적으로 유의한 상관계수를 보였다. 방울토마토는 완숙 토마토의 경우와 마찬가지로 봄에 가장 높은 구입액을 형성하고 있다. 한편 지역 구분에서는 완숙 토마토와 다르게 수도권이 광역시보다 높은 구입액을 형성하고 있는 것으로 나타났다.
인공신경망 모형과 고정효과 패널모형의 분석결과, 비교적 유사한 것을 확인할 수 있었다. 딸기의 경우, 인공신경망 모형에서 구입처와 가족구성원수, 연령, 계절 순으로 구입액에 영향을 미치는 것으로 나타났으며, 고정효과 모형 역시 계절, 구입처, 연령과 일부 가족구성원수에 통계적으로 유의한 결과값을 나타냈다.
파프리카를 분석한 결과, 소득, 연령, 소매업태, 계절 순으로 영향을 미치는 것으로 분석되었으나, 고정효과 모형에서는 계절과 일부 소매업태, 연령에서 유의미한 상관관계를 보이는 것으로 나타났다.
한편 완숙 토마토의 경우 인공신경망 모형에서 소매 구입 업태, 연령, 구입 지역, 계절에 영향을 받는 것으로 나타났으나, 패널 회귀분석 모형에서는 계절과 구입 지역, 일부 소매업태에서 유의미한 상관관계를 보였다. 따라서 인공신경망과 패널 회귀 분석모형에서 공통적으로 계절과, 지역, 소매업태가 소비자의 구입액에 영향을 미치는 것으로 나타났다. 한편 인공신경망은 연령과 소득에 대한 변수의 중요도를 고정효과 분석에 비해 크게 분석하였다.
마지막으로 방울토마토의 경우 인공신경망과 고정효과 분석모형에서 상이한 결과를 보였다. 인공신경망 모형의 경우 구입액에 대해 연령과 구입처, 가족구성원수, 소득과 지역에 상대적으로 높은 영향을 미치는 것으로 분석되었으며, 계절에 대해서는 큰 영향을 미치지 못하는 것으로 분석되었다. 한편 고정효과에서는 일부 지역과 소매업태에서 유의미한 결과를 보였으나, 인공신경망 모형과 반대로 계절 변수에 대해 가장 많은 통계적으로 유의미한 상관관계를 보였다.

Table 7은 위에서 분석한 인공신경망과 고정효과모형의 계수를 이용하여 가구의 구입액을 예측한 결과와 실제 구매액을 MSE를 통해 나타낸 결과이며, 해당 오차가 통계적으로 유의미함을 분석하는 DM 검정 결과를 의미한다. 분석결과, 인공신경망 모형을 통해 예측한 결과가 고정효과 모형의 예측한 결과보다 모든 품목에서 좋은 것으로 나타났다. 인공신경망 모형이 고정효과 모형보다 딸기의 경우 80.4%, 완숙 토마토의 경우 94.2%, 방울토마토의 경우 93.9%, 파프리카의 경우 90.7% 예측력이 상승한 것으로 나타났다. 또한, 이러한 예측력 차이를 통계적으로 검증하는 DM 검정 결과 완숙 토마토와 방울토마토는 1% 유의수준에서, 파프리카는 5% 유의수준에서 통계적으로 유의한 차이를 보였으며, 딸기의 경우 10% 유의수준에서 통계적으로 유의한 차이가 있는 것으로 나타났다.
본 연구는 농촌진흥청의 농식품 소비자패널 자료를 활용하여 각 가구의 어떤 특성이 주요 시설 과채류 소비를 위한 지출액에 영향을 미치는지 계량분석하고, 그리고 개별 가구의 시설 과채류의 지출액을 예측하였다. 분석모형은 패널모형과 함께 최근 사회적으로 빅데이터와 인공지능에 대한 관심이 높아지면서 주목받고 있는 인공신경망 모형을 활용하여, 기존 패널 회귀분석 방법과 각 가구의 과채류 소비지출액을 결정하는 요인들을 분석하고 소비지출액을 예측력을 비교하였다. 분석결과, 딸기의 경우 인공신경망 모형과 고정효과모형에서 공통적으로 품목을 구입하는 소매 업태와 소비자의 가족 구성원 수, 소비자의 연령이 구입액에 영향을 미치는 것으로 나타났으며. 완숙 토마토는 소매 업태와 구입하는 계절, 구입 지역이 중요한 영향을 미치는 것으로 나타났다. 방울토마토의 경우 소매 업태와 구입 지역이 공통적으로 구입액에 영향을 미치는 것으로 분석되었으며, 파프리카의 경우 계절과 연령이 중요한 영향을 미치는 것으로 나타났다. 한편 완숙토마토의 경우 연령과 소득이 구입액에 상대적으로 큰 영향력을 미치는 것으로 나타났으나, 고정효과 모형에서는 통계적으로 유의하지 않은 계수를 보였다. 또한, 방울토마토의 경우 가족 구성원 수와 소득에 상대적으로 큰 영향을 미치는 것으로 분석되었으나, 고정효과 모형에서는 유의하지 않은 계수로 나타났다.
한편 이를 통해 예측한 결과 인공신경망 모형이 고정효과 모형보다 예측 오차가 작게 나타났으며, 각 예측 오차의 차이가 통계적으로 유의미한 것으로 나타났다. 따라서 인공신경망 모형이 고정효과 모형보다 농식품 소비자 패널 자료의 패턴을 파악하는데 용이한 것으로 판단되며, 이를 통해 예측한 결과가 더 정확하게 나타난 것으로 보인다.
이러한 결과는 인공신경망 모형이 소비자의 선호를 판단하는데, 기존의 패널분석 모형보다 정확하게 요인을 분석하고 예측할 수 있는 것으로 나타났다. 따라서 최근 빠르게 변화하는 소비자의 농식품에 대한 소비패턴이나 구매에 미치는 요인을 기존의 패널 분석과 동시에 인공신경망을 통해 분석함으로써 소비자의 선택을 미리 예측할 수 있다. 이를 통해 농식품관련 다양한 의사결정을 통해 변화하는 시장에 유연하게 적용할 수 있을 것으로 예상된다. 특히 인공신경망은 파프리카와 같이 자료의 양이 적을 경우 반복 추정을 통해 결과를 얻을 수 있는 장점이 있다. 따라서 위와 같이 자료의 양이 적어 분석이 불가한 품목여도 적용할 수 있을 것으로 판단된다.
Footnote
1) Lee and Choi (1999)는 6가지의 과일류(사과, 배, 감귤, 포도, 감, 복숭아)와 4가지의 과채류(딸기, 참외, 수박, 토마토)를 대상으로 분석함.
2) 인공신경망은 입력층, 은닉층, 출력층으로 구성됨. 입력층은 분석에 사용되는 자료를 인공신경망 모형 내로 입력시키는 역할을 하는 단계이며, 입력된 데이터를 이용하여 하나 이상의 은닉층에서 활성함수를 통하여 계산을 진행함. 은닉층에서 계산된 결과는 출력층을 통해 인공신경망 모형의 결과로 도출함.
3) 활성화 함수는 은닉층 내에서 계산되는 함수를 의미하며, 일반적으로 시그모이드(sigmoid)함수, ReLu 함수, 하이퍼 볼릭 탄젠트(hyperbolic tangent)함수 등을 이용함. 본 연구에서는 수치 예측에 적합한 하이퍼볼릭 탄젠트 함수를 사용함.
4) 파프리카의 경우 이상치를 제거하기 위한 소비자 가격 자료가 2017년 1월부터 자료가 존재하기 때문에 2017년 1월부터 2018년 11월까지의 자료를 사용함.
5) 2차로 진행한 품목별 최소 단위 금액 이하를 이상치로 판단하여 제거하는 방법으로, 방울토마토와 완숙토마토는 500 g을, 파프리카는 200 g의 월평균 가격을 기준으로 이상치를 제거하였다. 딸기의 경우 패널 자료상 1 - 12월까지 구입액이 있으나, 소비자 가격이 1 - 6월, 11 - 12월까지 존재하여, Tukey (1977) 방법만을 이용하여 이상치를 제거하였다.

