
Introduction
수확로봇은 주행, 인식, 추종, 운반 등 복합적인 기술로 구성되며, 이 중 인식 기술의 경우 안정화된 로봇 수확을 위해 가장 우선 수행되어야 하는 주요 기술이다(Kim et al., 2022a). 로봇 수확 기술은 온실 등 정형화되어 있는 시설원예 환경에 적용하기 쉬우며, 국내에서는 시설원예 주요 작물 중 하나인 토마토를 대상으로 로봇 수확 기술 개발 및 적용 연구가 활발히 진행 중이다(Lee et al., 2022). 수확로봇의 객체 인식 기술은 대부분 작업 대상체 접근 후 수확 단계에서 주로 수행되었으며 기계 시각(machine vision)과 합성곱 신경망 기반의 딥러닝 기술이 최근 많이 활용되어 토마토의 2차원 객체 인식(Won et al., 2022) 및 3차원 위치 검출(Lee et al., 2022), 3차원 포즈 추정(Zhang et al., 2022), 6차원 포즈 추정(Kim et al., 2022c) 등 높은 성과를 보여주고 있다.
토마토 객체별 인식 기술은 주로 성숙단계 분류와 함께 수행되고 있으며, 일반적으로 영상 내 토마토들의 성숙단계와 위치 인식 후 대상과를 최종 선정하게 된다. 하지만 초기 넓은 범위를 포함하는 영상은 다양한 토마토 객체를 포함하고 있어 이러한 과정은 높은 정확성 및 많은 처리시간을 필요로 한다. 특히, 균일하게 성숙되지 않는 과채류의 생육 특성상 정확한 성숙단계의 구분이 모호할 뿐만 아니라 거리 증가에 따른 화질 저하로 로봇 수확의 성능을 감소시킬 수 있다(Kim et al., 2022b). 따라서, 초기 다양한 객체들이 존재하는 광범위 영상 내 완숙과가 밀집된 영역을 대략적이지만 빠르게 제공할 수 있다면 고효율 로봇 수확이 가능하다.
약지도 학습(weakly supervised learning)은 간단한 주석 작업으로 모델 학습을 수행하는 방법으로, 그 중 CAM (class activation map)을 이용한 객체의 지역화(localization)는 분류 수준의 주석작업으로 객체 검출 수준의 성능을 제공할 수 있어 작물 질병 검출(Kim et al., 2020) 등 주석된 데이터가 부족한 농업에 많이 활용되고 있다.
성숙 단계 판별을 위해서 최근 개발된 토마토 성숙도 분류모델의 경우 94% 수준의 높은 성능을 보여주고 있어(Kim et al., 2022b), 이러한 고성능 분류 학습 시 내재적인 지역화를 통해 완숙과 영역을 검출할 수 있다면 신속하게 수확 대상체 선정 및 접근이 가능하므로 로봇 수확 효율성 증가에 효과적이다.
본 연구는 로봇 수확 작업 시 인식 효율을 향상하기 위해 수행되었으며, 영상 내 완숙과 토마토 군집의 예상 영역을 검출하였다. 토마토 군집 영역은 합성곱 신경망 모델을 실제 온실에서 수집된 데이터로 분류 학습 후 내재적으로 학습된 위치정보를 CAM을 이용하여 검출되었다. 본 연구에서 제시된 토마토 군집 영역 검출 모델은 4개 층으로 구성되어 실시간성이 높으며 검출된 군집 영역은 수확 전 사전에 대상 범위를 줄여주므로 수확로봇 효율성 향상에 기여가 가능하다.
Materials and Methods
학습데이터 구성
완숙 토마토 군집 영역 검출을 위해 국립농업과학원 농업공학부에 위치한 토마토 시설온실에서 모니터링 로봇(Seo et al., 2021)을 이용하여 영상을 수집 및 실시간 저장하였다. 수집된 원 영상은 Fig. 1과 같으며, 학습데이터 구성을 위해 수집된 영상 내 토마토 객체 영역을 수작업으로 추출하였다. 이때, 객체 영역은 토마토 과실을 포함하는 최소의 사각형으로 설정하였다. 추출된 학습데이터는 모델의 입력 크기인 128 × 128 픽셀로 크기를 변경하였으며, 분류학습을 위해 수동으로 주석작업을 진행하였다.
토마토의 성숙 단계 분류는 일반적으로 녹숙기(green), 변색기(breaker), 채색기(turning), 도색기(pink), 담적색기(light red), 농적색기(red)의 6단계로 분류할 수 있으며(Huang et al., 2020), 본 연구에서는 모호함을 최소화하기 위해(Kim et al., 2022a) 중간단계를 줄여 녹숙기, 채색기, 도색기, 농적색기의 성숙도 4단계에 대해 분류학습을 진행하였으며, 전체 부류 수는 배경을 포함하여 총 5개로 구성되었다. 전체 데이터는 846장이며, 학습, 검증, 평가를 위해 각각, 591장(70%), 168장(20%), 87장(10%)을 사용하였다. 본 연구에서는 학습의 일반화성 향상을 위해 학습 데이터 증강을 수행하였으며, 좌우 및 상하 반전, 회전 등을 통해 실제 학습에 사용된 데이터는 총 2,028장으로 확장되며, 구체적인 구성은 Table 1과 같다.


토마토 군집 영역 검출 방법
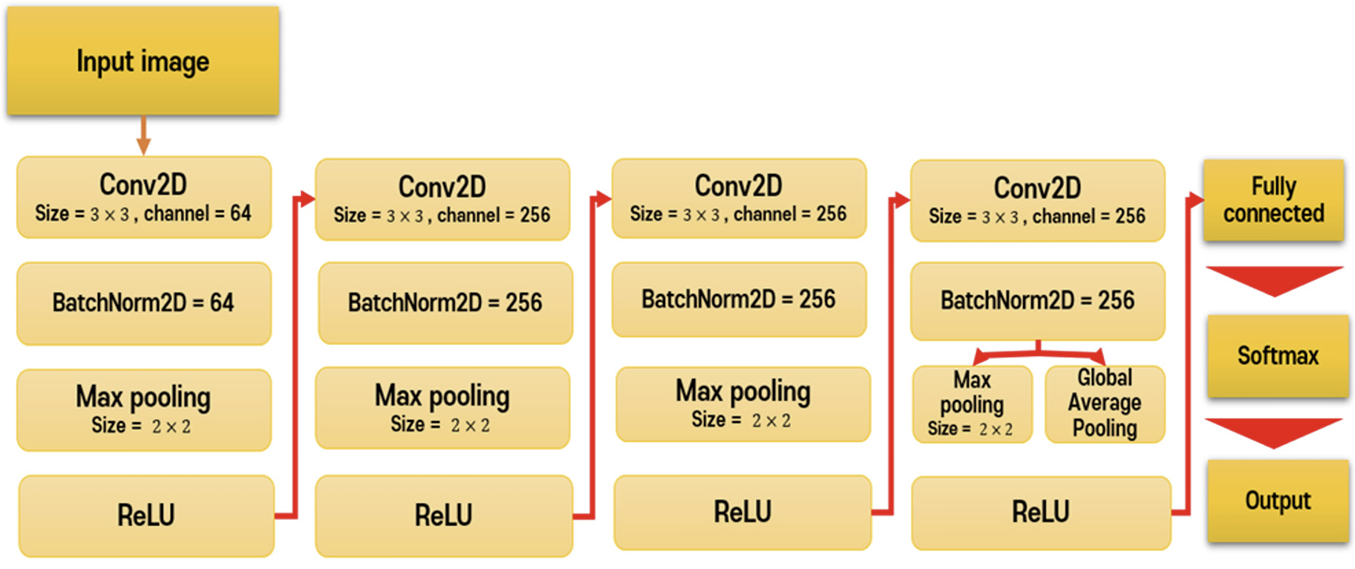
영역 검출은 단순 영상 수준의 주석 작업으로 분류와 동시에 영역 학습이 가능한 약지도 학습을 이용하였으며 분류 학습 결과로 만들어진 CAM (Zhou et al., 2016)을 사용하여 군집 영역을 나타내었다. CAM은 모델의 마지막 완전연결 계층을 GAP (global average pooling)로 대체하여 공간적 정보를 보존하며, 마지막 합성곱층(convolutional layer)을 지나는 특징과 GAP를 지난 특징의 가중치 합(weighted sum)을 통해 모델의 예측된 정보를 알 수 있다. Fig. 2는 학습 모델의 구성이며, 토마토의 경우 강인한 외형적 특성을 가지고 있지 않기 때문에 색상정보에 따른 분류 문제로 해결할 수 있다. 따라서 인식 속도 향상을 위해 4개의 층으로 구성된 모델 구조를 사용하였으며, 최종 특징맵(feature map)에서 Softmax 분류기로 성숙단계를 결정하였다.
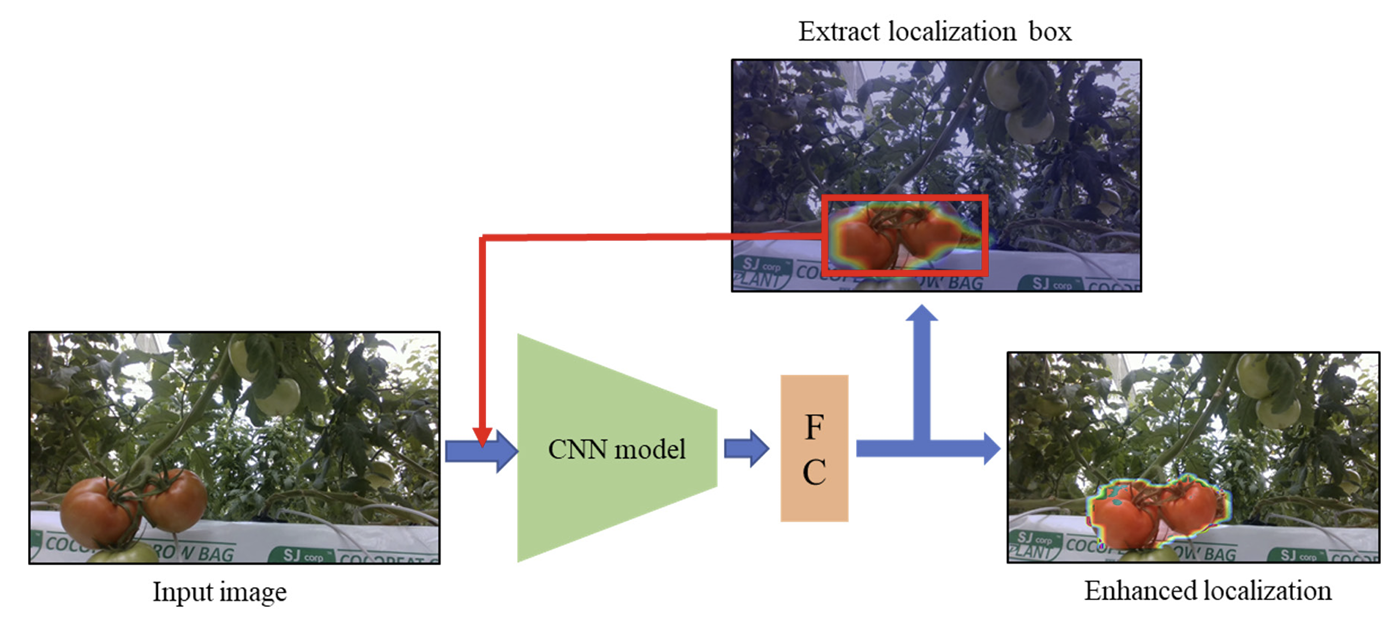
CAM을 사용한 군집 영역 검출은 대략적인 위치를 잘 나타내지만 군집의 국소적인 부분 혹은 보다 더 큰 범위를 제시하는 경향을 보이며 이때 전체 영역에 대한 정확한 정보를 포함할 수 없기 때문에 성능 저하가 발생할 수 있다.
따라서, 성능 향상을 위해서 Fig. 3과 같이 평가 시 CAM에서 활성화된 주요 영역에서 최대 영역의 왼쪽 상단 x 좌표, y 좌표와 너비(width), 높이(height) 값을 수집하여 해당 영역을 나타내는 가장 큰 bounding box를 추출하고, 추출된 영역을 다시 모델에 입력하는 재귀구조를 적용하여 정밀도를 향상시키는 방법을 제안한다.
성능 평가
분류 학습은 4단계의 성숙도에 배경을 포함한 5개 부류를 기준으로 진행되었으며, 완숙과 검출에 적합한 모델 선정을 위해 부류 수준에 따른 성능을 평가하였다. 부류 수준은 총 4가지 방법으로 설정하였으며, 성숙도 단계 및 배경 유무에 따라 차이가 있다. 각각은 배경이 포함된 성숙도 4단계, 배경이 미포함된 성숙도 4단계, 배경이 포함된 성숙도 2단계, 배경이 미포함된 성숙도 2단계이며, 이때, 2단계의 경우 중간단계를 제거한 형태로 녹숙기와 채색기, 도색기와 농적색기를 각각 같은 부류로 단계를 축소하여 평가를 진행하였다.
분류 성능은 대표적인 분류 성능 평가인 정확도(accuracy), 정밀도(precision), 재현율(recall), F1-score를 사용하였으며 각각 식(1) - (4)와 같다.
검출 영역에 대한 평가는 IoU (intersection over union)을 이용하였으며, 전체 평가샘플의 평균값인 mIoU (mean intersection over union)을 이용하여 성능을 비교하였다. 이때, IoU와 mIoU는 식(5), (6)과 같이 나타낼 수 있다.
여기서 n은 number of samples
학습 방법
완숙 토마토 영역 검출을 위한 학습은 300회 반복하였고 학습률(learning rate)은 0.0001, 배치 크기(batch size)는 64로 설정하였다. 최적화 알고리즘은 Adam optimizer를 이용하였으며, 모델 가중치는 과적합 방지를 위해 학습 중 검증데이터의 손실이 최소일 때의 값을 선정하였다.
모델은 GPU (GeForce RTX 3070ti, Nvidia, USA) 기반의 시스템으로 학습하였으며, 개발 언어는 python 3.7을 사용하였고, 대표적인 딥러닝 프레임워크(framework)중 하나인 pytorch 1.10을 사용하였다.
Results and Discussion
분류학습 결과
성숙도 분류 학습에 따른 손실(loss)은 Fig. 4와 같으며, 결과는 성숙도 단계 수에 따른 결과로 표현하였다. 토마토 분류의 경우 외형적 특성이 강하지 않은 간단한 픽셀 분류 수준의 문제로써 모든 경우에서 손실이 0으로 수렴되어 정상적인 학습이 가능한 것으로 판단되며 Fig. 4c와 4d의 경우 상대적으로 진동 없이 빠르게 수렴이 가능한 것으로 보아 모호한 중간 단계를 제거할수록 학습이 더욱 용이함을 알 수 있다.
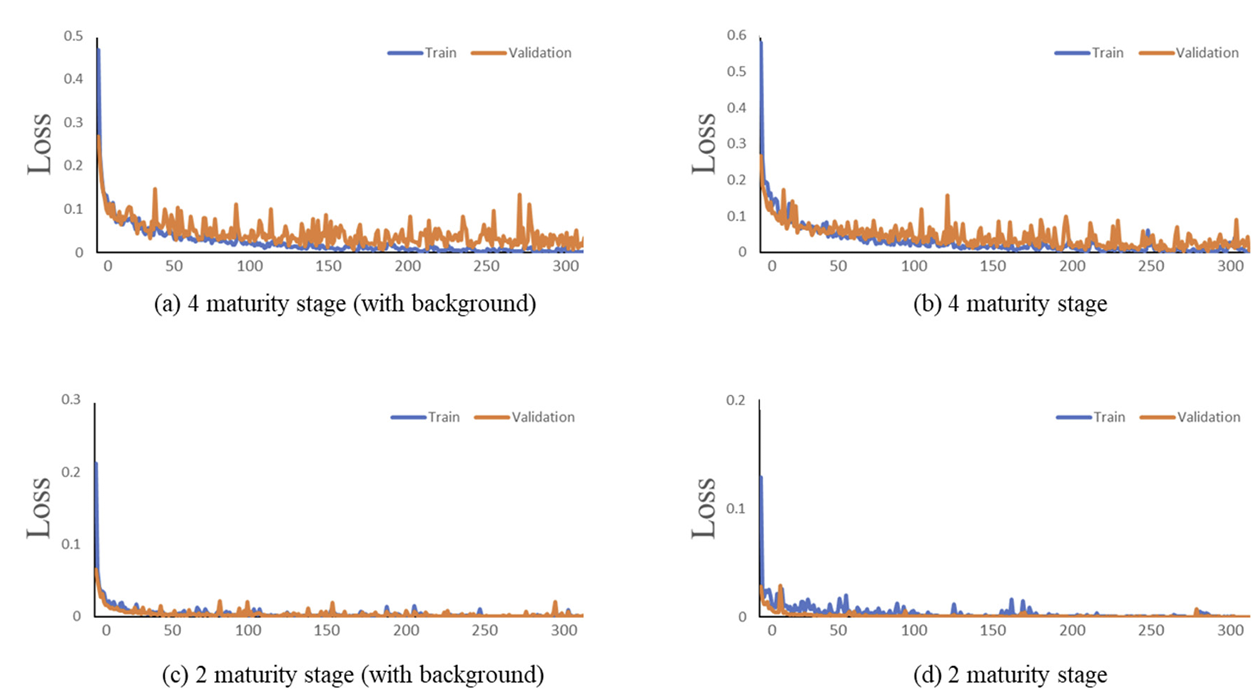
Table 2는 성숙도 분류 학습의 성능 평가 결과로 각각의 값은 평가샘플들의 평균으로 표현되었다. 분류해야 될 부류가 많아질수록 일반적으로 성능이 다소 낮아졌지만, 대부분 0.9 이상으로 높은 정확도를 보여주었다. 배경이 포함된 5개 부류의 분류학습에서는 정밀도가 0.87로 가장 낮아 다른 경우에 비해 오검출이 높음을 알 수 있다.

토마토 군집 영역 검출
분류 학습 모델의 CAM을 이용한 토마토 군집 영역 검출 결과는 Fig. 5와 같이 관찰되었다. 영역 검출 결과는 색상맵(colormap) 중 히트맵(heatmap) 방식을 이용하여 시각화하였다. Fig. 5a는 배경을 포함한 성숙 4단계 분류 학습 모델을 이용한 영역 검출 결과로 전반적인 군집 영역이 검출됨을 확인 할 수 있으며 Fig. 5d는 성숙 2단계 분류 학습 모델을 이용한 군집 영역 검출 결과로 군집의 아주 작은 부분만을 포함하거나 검출이 실패한 경우가 관찰되는 등 전반적으로 정상적인 형태 검출의 어려움이 관찰되었다.

Table 3은 영역 검출 성능을 모델별로 비교한 것이며 4부류(배경 포함) 분류 모델에서 0.52 수준의 mIoU를 보여주었다. 이는 성숙도 분류 학습 중 내재적으로 학습된 영역 검출이 완숙과 군집 검출에 효과적으로 활용될 수 있음을 보여준다.

분류 모델 중 영역 검출 성능이 가장 높은 4부류(배경포함) 분류모델을 기준으로 재귀 방식의 추론을 통해 성능을 향상시켰으며, 그 결과는 Fig. 6과 같다.

제안된 방법은 완숙 토마토 영역에 집중을 가속화할 수 있어 시각적으로 보다 정확한 영역을 제시할 수 있었다. Table 4는 재귀 방식의 적용에 따른 성능 변화이며 mIoU가 0.52에서 0.65로 약 13% 증가함을 알 수 있다. 따라서, 본 제안 방식을 통해 완숙 토마토 군집 영역을 모델의 구조 변화 없이 더 정확하게 검출할 수 있었으며, 반복적인 적용을 통해 정확도 향상이 가능할 것으로 기대된다.

Conclusion
본 연구는 토마토 수확로봇의 자동 수확 및 관리를 위한 연구로써 간단한 주석 작업으로 적용 가능한 약지도 학습의 가중치로 class activation map을 작성하여 수확 전 완숙과 군집 영역의 위치를 제공할 수 있는 방법을 제안하였으며, 보다 정확한 검출을 위한 성능 향상 방법을 제안하였다. 현장에서 취득한 토마토 영상을 기반으로 학습을 위한 데이터세트를 구성하였으며, 배경 유무와 성숙 단계에 따른 4가지 데이터셋을 구성하여 학습을 진행하였다.
토마토는 외형적 특성이 강하지 않은 간단한 픽셀 분류 수준의 문제로서 모든 경우에서 손실이 0으로 수렴되어 정상적인 학습이 가능한 것으로 판단되며, 분류해야 될 부류가 많아질수록 정밀도, 재현율, F1-score가 감소하였지만, 대부분 0.9 이상으로 높은 정확도를 보여주었다. 배경이 포함된 5개 부류의 분류학습에서는 정밀도가 0.87로 다른 경우에 비해 오검출이 높음을 알 수 있다.
시각적인 영역 검출은 배경이 포함된 4단계 분류에서 가장 좋은 검출 성능을 보였으며, mIoU 는 0.52 수준으로 의미 있는 결과가 관찰되었다.
Class activation map을 이용한 영역 검출 결과는 국소적인 위치를 검출하거나 팽창된 위치를 검출하는 경향을 보였으며 영역 검출을 보다 정교하게 만들기 위해 재귀 방식의 영역 재추론 방법을 적용하여 성능을 향상시켰다.
배경을 포함한 4단계 부류 모델에서 해당 추론을 적용해 보았을 때 mIoU 가 0.52 에서 0.65로 13% 상승된 것을 확인할 수 있었다.
본 연구를 통해 수확로봇의 수확량 증가를 위한 수확 전 완숙과 군집의 대략적인 영역 검출이 가능하였으며, 재귀 방식의 재추론 과정을 적용하여 보다 정밀한 영역 검출이 가능하였다. 본 연구의 경우 과실 수확을 위한 구체적인 정보 제공 및 직접적으로 제어에 활용이 어렵다는 한계가 존재한다. 하지만 제안된 재귀 방식의 경우 넓고 대략적인 영역에서 구체적인 영역으로 점차 영상의 초점을 이동시킬 수 있는 정보를 제공할 수 있으므로 대상 시스템에 최적화를 통해 수확로봇의 제어에 충분히 기여 가능할 것으로 판단된다.

